- Die Infrastrukturlücke, über die niemand spricht
- Was ist eigentlich ein LLM-Proxy?
- Warum dieses Problem gerade jetzt so dringlich ist
- Kernfunktionen eines LLM-Proxys für den produktiven Einsatz
- Sicherheitsarchitektur: Mehrschichtige Verteidigung für KI-Systeme
- Governance: Vom experimentellen Instrument zum verwalteten System
- Die ehrlichen Kompromisse
- Wo dies hinführt
Die Infrastrukturlücke, über die niemand spricht
KI im Unternehmensbereich hat eine neue Schwelle überschritten. Was als vereinzelte Experimente mit ChatGPT-Integrationen und Proof-of-Concept-Chatbots begann, hat sich zu produktionsreifen Lösungen entwickelt: Support-Mitarbeiter mit Kundenkontakt, interne Co-Piloten für Entwickler, Echtzeit-Analysepipelines und zunehmend auch autonome Multi-Agenten-Workflows.
Doch hier ist die unangenehme Wahrheit, die die meisten Entwicklerteams auf die harte Tour erfahren müssen: Die Ausweitung des Einsatzes von LLMs ohne eine Kontrollschicht ist eine tickende Zeitbombe. Am Ende häufen sich fragmentierte API-Integrationen, unvorhersehbare Token-Kosten, Sicherheitslücken und eine Compliance-Situation an, die Prüfer bei der Überprüfung nicht gerne sehen werden.
Die Lösung liegt nicht in zusätzlichen Tools auf der Anwendungsebene. Es handelt sich vielmehr um eine spezielle Middleware-Schicht, die zwischen Ihren Anwendungen und Ihren KI-Anbietern angesiedelt ist, in der Branche als LLM-Proxy bezeichnet. Für jedes Unternehmen, das KI im Produktivbetrieb einsetzt, ist dies kein blosses „Nice-to-have“. Es handelt sich um grundlegende Infrastruktur.
Was ist eigentlich ein LLM-Proxy?
Ein LLM-Proxy ist ein zentraler Zugangspunkt, der den gesamten Datenverkehr zwischen Ihren Anwendungen und einem oder mehreren LLM-Anbietern vermittelt: OpenAI, Anthropic, Google Gemini, lokale Modelle, ganz gleich, was Ihr Stack umfasst.
Anstatt dass jeder Dienst seine eigene direkte Anbindung an die APIs einzelner Anbieter unterhält, laufen alle Anfragen über einen einzigen kontrollierten Endpunkt. Der Proxy übernimmt dann für alle aufrufenden Dienste einheitlich die Authentifizierung, die Formatierung der Anfragen, die Weiterleitung an die Anbieter, die Durchsetzung von Richtlinien und die Überwachbarkeit.
Wenn Sie bereits mit Begriffen wie API-Gateways oder Service Meshes vertraut sind, lässt sich das Konzept leicht nachvollziehen. Ein LLM-Proxy verhält sich zum KI-Datenverkehr wie ein API-Gateway zu REST-Diensten, nur dass hier mehr auf dem Spiel steht, die Nutzdaten semantisch komplexer sind und die Fehlerquellen deutlich weniger vorhersehbar sind.
Eine vereinfachte Darstellung der Architektur sieht wie folgt aus:
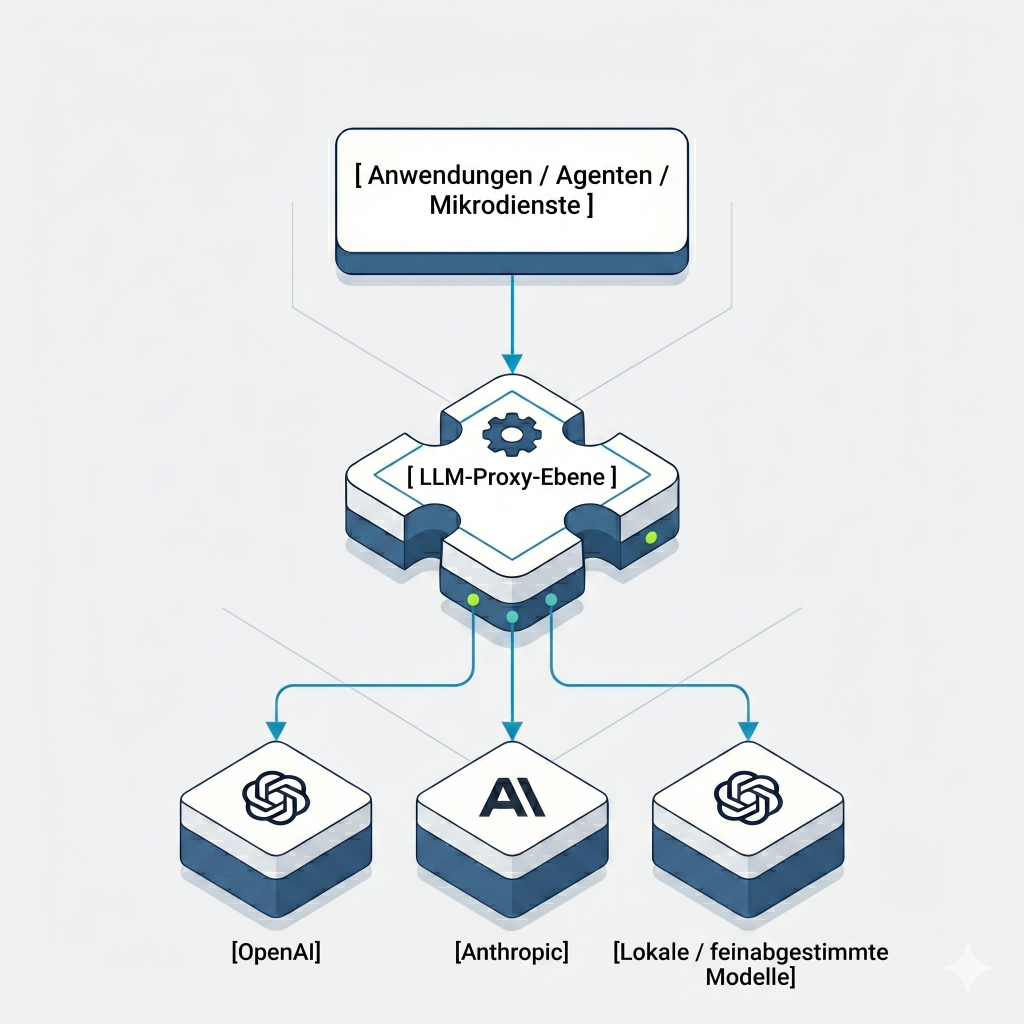
Ein Einstiegspunkt. Volle Kontrolle. Einheitliches Verhalten, unabhängig davon, was nachgeschaltet läuft.
Warum dieses Problem gerade jetzt so dringlich ist
Die Ausbreitung der KI hat in Ihrem Unternehmen bereits begonnen
In den meisten Unternehmen wird die Einführung von KI nicht zentral koordiniert. Sie erfolgt Team für Team. Ein Team integriert GPT-4o für die Zusammenfassung von Texten. Ein anderes testet Claude für die Codeüberprüfung. Ein Datenteam nutzt Gemini für die strukturierte Datenextraktion. Jedes Team wählt den Anbieter, der seinen Anforderungen hinsichtlich Latenz, Kosten oder Qualität zum jeweiligen Zeitpunkt am besten entspricht.
Das Ergebnis ist ein Wirrwarr an Integrationen, von denen jede ihre eigene Authentifizierungslogik, Fehlerbehandlung und Wiederholungsstrategien hat. Die Wartung wird zur Qual. Das Verhalten wird inkonsistent. Wenn ein Anbieter seine API ändert oder ein Modell als veraltet kennzeichnet, muss man den Code an Dutzenden Stellen anpassen.
Ein LLM-Proxy fasst diese Komplexität in einer einzigen Schnittstelle zusammen. Multi-Modell-Strategien werden so zu einer operativen Entscheidung auf Proxy-Ebene und sind nicht mehr Gegenstand eines Entwicklungsaufwands, der sich auf alle Teams verteilt.
Der Fluss sensibler Daten über unkontrollierte Endpunkte ist ein echtes Problem
Grosse Sprachmodelle (LLMs) bearbeiten nicht nur einfache Anfragen. Sie verarbeiten Kundeneingaben, interne Dokumente, Finanzdaten und firmeneigene Geschäftslogik. Ohne eine vorangeschaltete Kontrollschicht setzen Sie die API-Endpunkte Risiken aus, die sich vollständig vermeiden lassen:
- Angriffe durch Prompt-Injection
- Versehentliche Übermittlung personenbezogener Daten an Drittanbieter
- Unbefugte Nutzung von API-Schlüsseln
- Modellausgaben, die gegen Ihre eigenen Inhaltsrichtlinien verstossen
Ein ordnungsgemäss implementierter LLM-Proxy fungiert als mehrschichtige Sicherheitsmassnahme, die Eingaben überprüft, bevor sie ein Modell erreichen, und Ausgaben filtert, bevor sie einen Nutzer erreichen. Bei N47, wo wir nach ISO 27001 zertifiziert sind, ist eine solche systematische Sicherheitsarchitektur kein nachträglicher Einfall. Sie ist die grundlegende Erwartung an jedes Produktionssystem, das wir entwickeln oder bei dessen Umsetzung wir beraten.
Die Compliance-Anforderungen werden immer strenger
Das EU-KI-Gesetz ist kein Zukunftsprojekt mehr. Unternehmen, die in regulierten Umgebungen tätig sind, müssen die Rückverfolgbarkeit von Daten, den kontrollierten Zugriff auf KI-Funktionen und die Nachprüfbarkeit von Interaktionen nachweisen. Ohne eine zentralisierte Protokollierung und Governance ist dies kaum nachzuweisen.
Ein LLM-Proxy bietet Ihnen eine zentrale Anlaufstelle, über die Sie die Durchsetzung von Richtlinien, die lückenlose Protokollierung von Anfragen und Antworten sowie Zugriffskontrollen in grossem Massstab umsetzen können, anstatt Compliance-Massnahmen nachträglich in jede einzelne Anwendung integrieren zu müssen.
Die Kosten für Token steigen schneller, als die Teams erwarten
Die Preise für LLM richten sich nach dem Verbrauch, und die Rechnung steigt mit jeder neuen Funktion, jedem neuen Nutzer und jeder ineffizienten Eingabeaufforderung. Ohne Einblick darin, welche Teams was verbrauchen, werden die Kosten undurchsichtig. Entwickler duplizieren unbeabsichtigt Anfragen. Veraltete Integrationen leiten alles an Premium-Modelle weiter, obwohl günstigere Alternativen die Aufgabe genauso gut erfüllen würden.
Ein Proxy ermöglicht Ihnen eine zentralisierte Kostenüberwachung, aufgeschlüsselt nach Benutzer, Team oder Anwendung. Er ermöglicht die Einhaltung von Budgets, die Verwaltung von Kontingenten und intelligentes Routing, sodass Sie automatisch auf kostengünstigere Modelle zurückgreifen, wenn die Aufgabe die Nutzung einer Premium-Stufe nicht rechtfertigt.
Kernfunktionen eines LLM-Proxys für den produktiven Einsatz
Einheitliche API-Abstraktion
Entwickler müssen nur einmal eine Schnittstelle zum Proxy integrieren. Anbieterspezifische Besonderheiten wie Authentifizierungsverfahren, Anforderungsformate und Antwortstrukturen werden abstrahiert. Der Wechsel zu einem anderen Anbieter oder das Hinzufügen neuer Anbieter erfordert lediglich eine Konfigurationsänderung und keinen technischen Aufwand.
Intelligentes Routing und Orchestrierung
Proxys können Modelle dynamisch auf der Grundlage von Echtzeit-Signalen auswählen: Kostenbeschränkungen, Latenzschwellen, Aufgabenkomplexität oder aktuelle Verfügbarkeit der Anbieter. Eine einfache FAQ-Anfrage wird an ein schlankes, kostengünstiges Modell weitergeleitet. Eine komplexe, mehrstufige Schlussfolgerungsaufgabe wird an ein Premium-Modell weitergeleitet. Dies geschieht transparent, ohne dass die aufrufende Anwendung davon Kenntnis haben oder sich darum kümmern muss.
Sicherheits-Leitplanken
Proxys für Unternehmen gewährleisten:
- Bereinigung von Eingaben und Schwärzung personenbezogener Daten
- Erkennung von Injektionen
- Moderation von Ausgaben
- Ratenbegrenzung
All dies wird bei jeder Anfrage einheitlich angewendet, unabhängig davon, von welcher Anwendung sie stammt. Die Alternative wäre, dieselben Kontrollen in jedem Dienst redundant zu implementieren, was unweigerlich zu Lücken führt.
Umfassende Beobachtbarkeit
Die Token-Nutzung, Latenzverteilungen, Fehlerraten und Prompt-Muster werden über eine einzige Beobachtungsoberfläche sichtbar. Das sind die Daten, die Sie benötigen, um Probleme in der Produktion zu beheben, die Leistung zu optimieren und zu verstehen, wie KI-Funktionen tatsächlich genutzt werden, und nicht nur, wie Sie angenommen haben, dass sie genutzt werden.
Governance und Zugriffskontrolle
Eine rollenbasierte Zugriffskontrolle auf Proxy-Ebene ermöglicht es Ihnen, festzulegen, welche Teams welche Modelle nutzen dürfen, organisatorische Kontingente durchzusetzen und API-Schlüssel zentral zu verwalten, anstatt Anmeldedaten über die Konfigurationen der einzelnen Dienste zu verstreuen. Dies ist zudem die praktische Lösung für das Problem der „Schatten-KI“, also Teams, die KI-Integrationen völlig ausserhalb der Sichtbarkeit der Organisation einrichten.
Sicherheitsarchitektur: Mehrschichtige Verteidigung für KI-Systeme
Sicherheit in KI-Systemen erfordert einen mehrschichtigen Ansatz, und der LLM-Proxy ist der Punkt, an dem diese Schichtung praktisch umsetzbar wird. Die Kontrollmassnahmen lassen sich in vier Bereiche unterteilen:
- Eingabekontrollen: Bereinigung von Eingaben, Erkennung von Injektionen und Schwärzung personenbezogener Daten, bevor Daten Ihre Umgebung verlassen
- Ausgabekontrollen: Filterung toxischer Inhalte und Verhinderung von Datenlecks, damit die Modellantworten Ihren Inhalts- und Compliance-Standards entsprechen
- Laufzeitkontrollen: Ratenbegrenzung und Erkennung von Anomalien zum Schutz vor Missbrauch und unerwarteten Nutzungsspitzen
- Audit- und Compliance-Kontrollen: Vollständige Protokollierung von Anfragen und Antworten mit der für behördliche Audits erforderlichen Rückverfolgbarkeit
Der entscheidende Unterschied besteht darin, dass sich die Implementierung dieser Kontrollen auf Proxy-Ebene grundlegend von der anwendungsspezifischen Umsetzung unterscheidet. Auf Anwendungsebene hinkt man ständig hinterher, da ständig neue Dienste entwickelt werden. Auf Proxy-Ebene werden die Kontrollen einmalig angewendet und von allen Komponenten übernommen.
Governance: Vom experimentellen Instrument zum verwalteten System
Der Wandel von „Wir experimentieren mit KI“ hin zu „KI ist eine fest verankerte organisatorische Kompetenz“ ist im Wesentlichen eine Frage der Steuerung, und LLM-Proxies sind der Mechanismus, durch den dieser Wandel tatsächlich stattfindet.
„Policy-as-Code“ bedeutet, dass sich Ihre Governance-Strategie weiterentwickelt, ohne dass koordinierte Änderungen in jeder einzelnen Anwendung erforderlich sind. Audit-Trails liefern Ihnen eine lückenlose Aufzeichnung jeder KI-Interaktion, was immer wichtiger wird, da Unternehmen zunehmend auf agentenbasierte KI-Systeme umsteigen, bei denen autonome Agenten Entscheidungen treffen und im Namen der Nutzer externe Tools aufrufen.
Die Standardisierung gewährleistet ein einheitliches Modellverhalten über verschiedene Anwendungsfälle hinweg und verhindert so, dass zwei Teams, die „dieselbe“ KI-Funktion nutzen, völlig unterschiedliche Ergebnisse erzielen, weil sie die Konfiguration unterschiedlich vorgenommen haben.
Mit der Weiterentwicklung von Multi-Agenten-Architekturen, in denen KI-Agenten miteinander vernetzt sind, Tools nutzen und mit externen Diensten interagieren, entwickelt sich der LLM-Proxy von einem Traffic-Gateway zu einer vollwertigen KI-Steuerungsebene. Er wird zur Ebene, die sichere Autonomie in grossem Massstab gewährleistet.
Die ehrlichen Kompromisse
LLM-Proxys bieten einen echten Mehrwert, doch Entwicklerteams sollten sich über die damit verbundenen Kosten im Klaren sein.
Jede Anfrage, die über den Proxy läuft, verursacht eine gewisse Latenz. Überprüfung, Routing-Logik und Protokollierung sind nicht kostenlos. Gut konzipierte Implementierungen halten diesen Overhead zwar minimal, doch für latenzempfindliche Anwendungen ist dies ein wichtiger Faktor. Auch die Pflege der Richtlinien ist eine fortlaufende operative Aufgabe: Die Sicherheitsvorkehrungen müssen getestet, angepasst und aktualisiert werden, wenn sich Modelle und Anwendungsfälle weiterentwickeln. Zu aggressive Filter erzeugen Fehlalarme, die legitime Anfragen blockieren und für Entwickler zu Reibungsverlusten führen. Und wie jedes Infrastrukturkomponente erfordert auch der Proxy selbst Überwachung, Verantwortungszuweisung und betriebliche Reife.
Das sind keine Gründe, Proxys zu meiden. Es sind Gründe, sie wohlüberlegt zu implementieren, mit derselben technischen Sorgfalt, die man bei jedem kritischen Bestandteil der Produktionsinfrastruktur an den Tag legen würde.
Wo dies hinführt
Der LLM-Proxy ist keine Übergangsarchitektur. Je weiter Unternehmen bei KI-Fähigkeiten voranschreiten, man denke an Echtzeit-Entscheidungsmaschinen, durch Tools unterstützte Agenten und Pipelines zur Orchestrierung mehrerer Modelle, desto grösser wird der Bedarf an einer zentralisierten Steuerungsebene. Unternehmen, die diese Ebene frühzeitig aufbauen, verschaffen sich einen strukturellen Vorteil: die Fähigkeit, neue Modelle einzuführen, neue Vorschriften einzuhalten und den KI-Einsatz zu skalieren, ohne jedes Mal, wenn sich etwas ändert, ihre Grundlagen neu aufbauen zu müssen.



