In der heutigen datengesteuerten Welt hantieren Unternehmen mit immer grösseren Datenmengen, die effizient und zuverlässig verarbeitet werden müssen. Ganz gleich, ob du das Nutzerverhalten in Echtzeit analysierst, grosse Datensätze für das Reporting transformierst oder Machine-Learning-Pipelines aufbaust: Moderne Datensysteme müssen flexibel, skalierbar und wartbar sein. Genau hier kommt Apache Beam ins Spiel. Apache Beam ist ein quelloffenes, vereinheitlichtes Programmiermodell, das entwickelt wurde, um die Datenverarbeitung im grossen Stil zu vereinfachen. Damit kannst du sowohl Batch- als auch Stream-Processing-Pipelines über eine einzige Abstraktion definieren, die sich anschliessend auf verschiedenen Backends für die verteilte Verarbeitung ausführen lässt. In diesem Blogpost schauen wir uns mal an, was Apache Beam eigentlich ist, warum es so nützlich ist und wie es in das moderne Daten-Ökosystem passt.
Was ist Apache Beam?
Apache Beam ist ein Programmiermodell sowie ein Set von SDKs, um Datenverarbeitungspipelines zu definieren und auszuführen. Anstatt deine Logik an eine spezifische Execution-Engine zu binden, schreibst du deine Pipeline mit Beam nur ein einziges Mal und lässt sie auf verschiedenen Runnern wie Apache Flink, Apache Spark oder Google Cloud Dataflow laufen. Der Kerngedanke hinter Beam ist die Trennung von Zuständigkeiten:
- Du definierst, was deine Pipeline tun soll.
- Der Runner entscheidet, wie dies effizient ausgeführt wird.
Diese Abstraktion ermöglicht es Teams, einen Vendor-Lock-in zu vermeiden und sich an veränderte Infrastrukturanforderungen anzupassen, ohne die eigentliche Geschäftslogik umschreiben zu müssen.
Warum Apache Beam nutzen?
1. Einheitliches Batch- und Streaming-Modell
Klassischerweise erforderten Batch- und Stream-Verarbeitung separate Systeme und Codebasen. Apache Beam vereint beide Paradigmen in einem einzigen Modell. Das bedeutet für dich: Du schreibst eine Pipeline, die gleichermassen funktioniert für:
- Historische Daten (Batch)
- Echtzeitdaten (Streaming)
Beam kümmert sich dabei um die Komplexität von Event-Time, Windowing und verspätet eintreffenden Daten, was den Aufbau konsistenter Pipelines erheblich erleichtert.
2. Portabilität durch verschiedene Runner
Beam-Pipelines sind portabel. Du kannst dieselbe Pipeline auf unterschiedlichen Execution-Engines (den sogenannten Runnern) ausführen, wie zum Beispiel:
- Apache Flink
- Apache Spark
- Google Cloud Dataflow
Diese Flexibilität ist besonders wertvoll für Organisationen, die sich nicht an einen einzelnen Anbieter binden wollen oder ihre Infrastruktur im Laufe der Zeit migrieren müssen.
3. Skalierbarkeit
Da Beam-Pipelines auf verteilten Systemen laufen, lassen sie sich horizontal skalieren, um massive Datensätze zu bewältigen. Ob du nun mit Gigabytes oder Petabytes an Daten arbeitest – Beam ermöglicht dir eine effiziente parallele Verarbeitung.
4. Fortgeschrittenes Windowing und Zeit-Semantik
Zeitkorrekte Verarbeitung in Streaming-Systemen gilt als extrem schwierig. Beam bietet hierfür robuste Unterstützung:
- Verarbeitung der Event-Time
- Windowing (Fixed, Sliding, Session Windows)
- Watermarks zur Fortschrittsverfolgung
- Trigger zur Steuerung des Output-Timings
Dadurch kannst du präzise und zuverlässige Echtzeit-Analysesysteme realisieren.
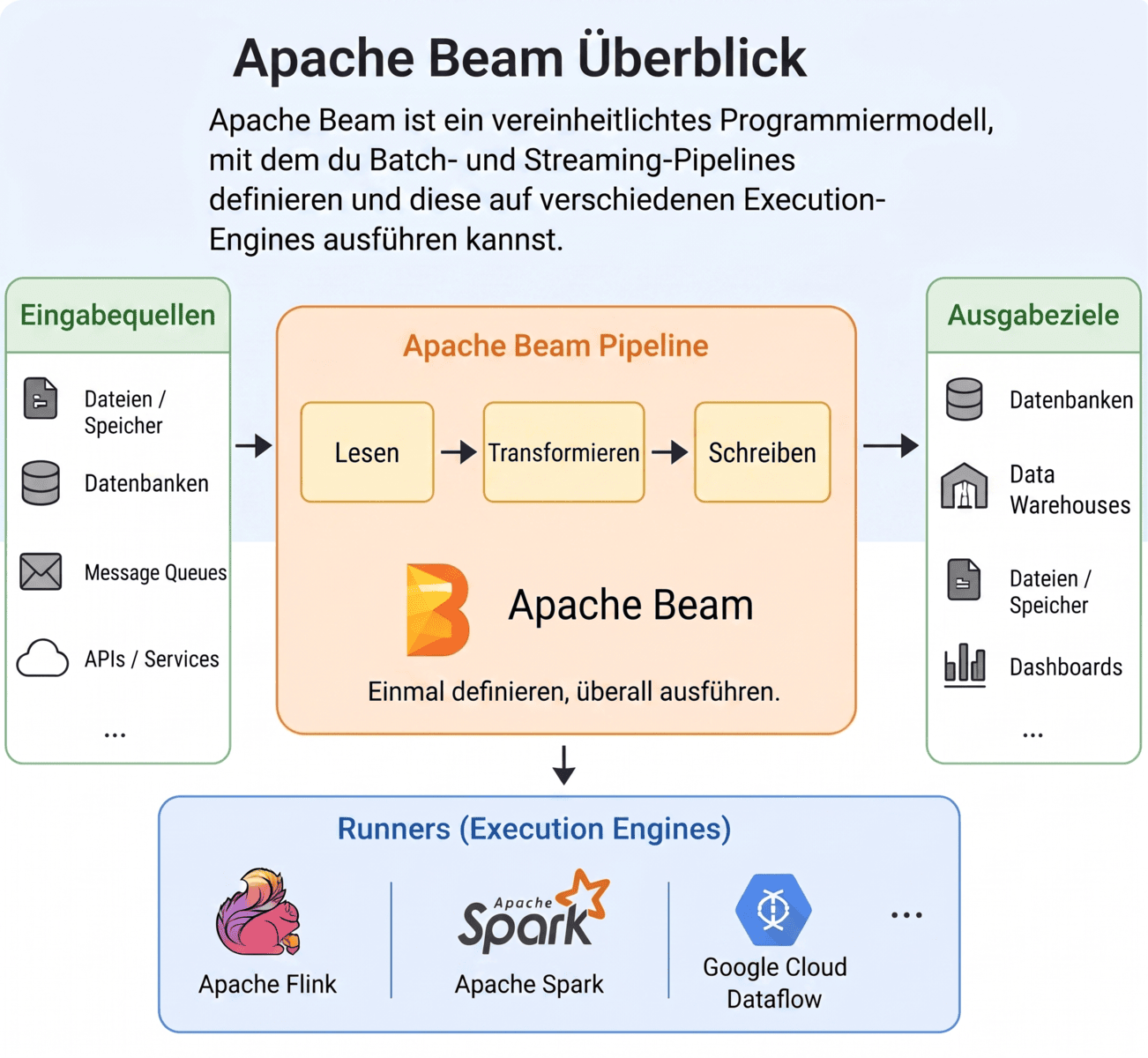
Core Concepts in Apache Beam
Um zu verstehen, wie Apache Beam eigentlich tickt, solltest du dich mit den zentralen Abstraktionen vertraut machen. Diese bilden das Fundament jeder Pipeline.
1. Pipeline
Eine Pipeline stellt den gesamten Workflow der Datenverarbeitung dar. Sie definiert die Abfolge der Schritte, die deine Eingabedaten in die gewünschten Ausgabedaten transformieren. Du kannst sie dir wie einen gerichteten Graphen vorstellen, der den Weg deiner Daten beschreibt.
2. PCollection
Eine PCollection repräsentiert einen verteilten Datensatz. Dabei ist es egal, ob dieser «bounded» (begrenzt, also Batch) oder «unbounded» (unbegrenzt, also Streaming) ist. Betrachte sie einfach als eine grosse, unveränderliche (immutable) Sammlung von Datenelementen, die über das Cluster verteilt sind.
3. PTransform
Ein PTransform definiert eine Operation, die auf eine PCollection angewendet wird – zum Beispiel das Filtern, Gruppieren oder Aggregieren von Daten. Zu den gängigsten Transforms gehören:
- Map: Wandelt Elemente einzeln um.
- Filter: Sortiert unerwünschte Daten aus.
- GroupByKey: Gruppiert Daten anhand eines gemeinsamen Schlüssels.
- Combine: Führt Werte effizient zusammen.
4. DoFn
Eine DoFn (kurz für „Do Function“) ist eine von dir definierte Funktion, die einzelne Elemente innerhalb einer PCollection verarbeitet. Sie kommt meist innerhalb von Transforms wie ParDo zum Einsatz, um deine ganz eigene Logik abzubilden. Hier schreibst du also den eigentlichen Code, der bestimmt, was mit jedem Datensatz passieren soll.
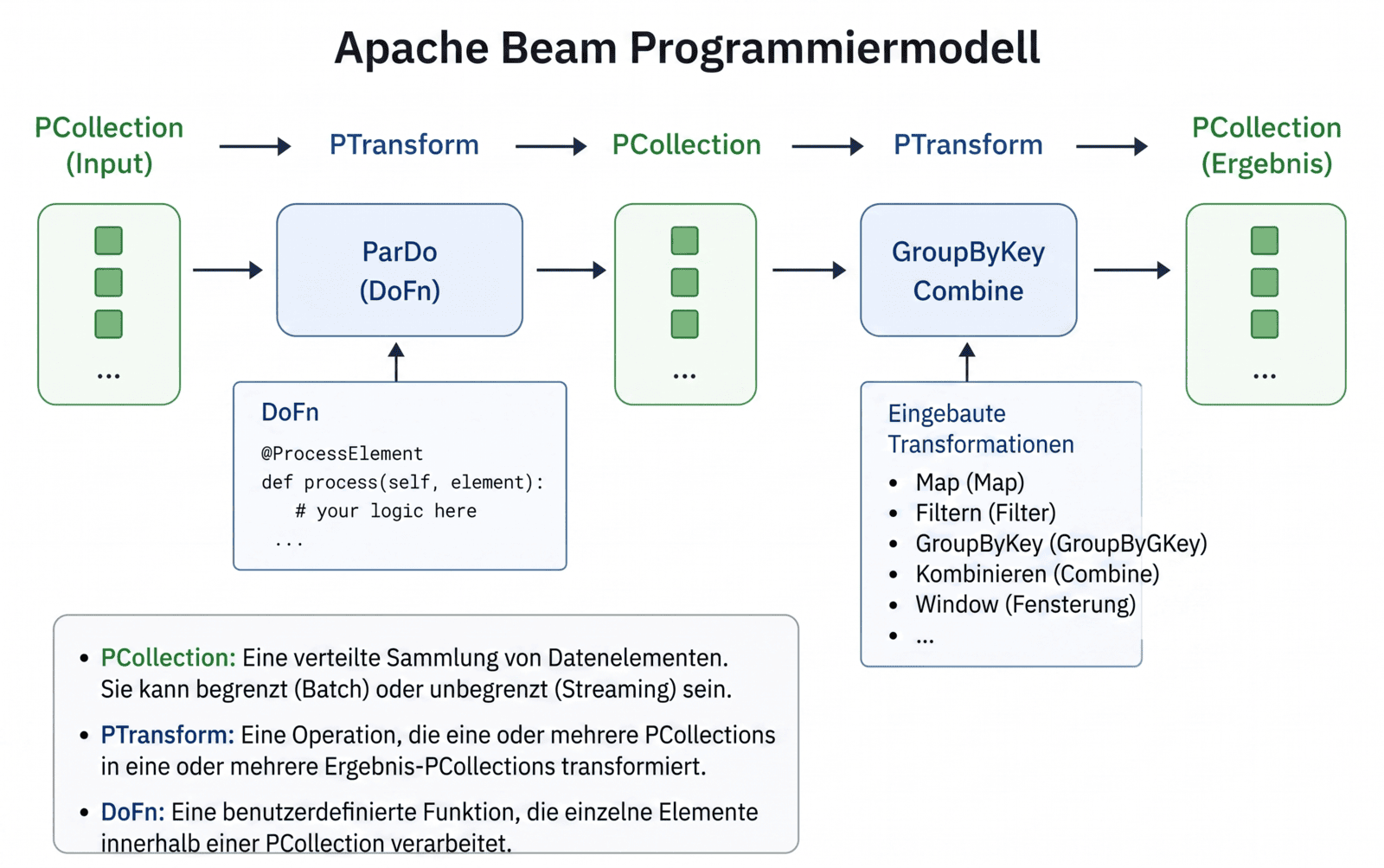
5. Runner
Der Runner ist die Execution-Engine, die deine Pipeline letztlich ausführt. Da Beam verschiedene Runner unterstützt, profitierst du von maximaler Portabilität und Flexibilität – du entscheidest selbst, wo deine Workloads laufen sollen.
Beispiel-Workflow
Eine typische Apache-Beam-Pipeline lässt sich in drei grundlegende Schritte unterteilen:
- Daten aus einer Quelle lesen (z. B. aus einer Datei, einer Datenbank oder einer Message Queue).
- Transformationen anwenden (Filtern, Mapping, Aggregieren).
- Ergebnisse in einen Sink schreiben (z. B. in eine Datenbank, ein Data Warehouse oder ein Dateisystem). Stell dir vor, du möchtest Clickstream-Daten verarbeiten. Das Ganze könnte so aussehen:
- Events aus einer Streaming-Quelle wie Kafka auslesen.
- Events nach Benutzern gruppieren.
- Die jeweilige Session-Dauer berechnen.
- Ergebnisse an ein Dashboard oder ein Analysesystem ausgeben.
Mit Beam lässt sich dieser komplette Workflow in einer einzigen, einheitlichen Pipeline abbilden.
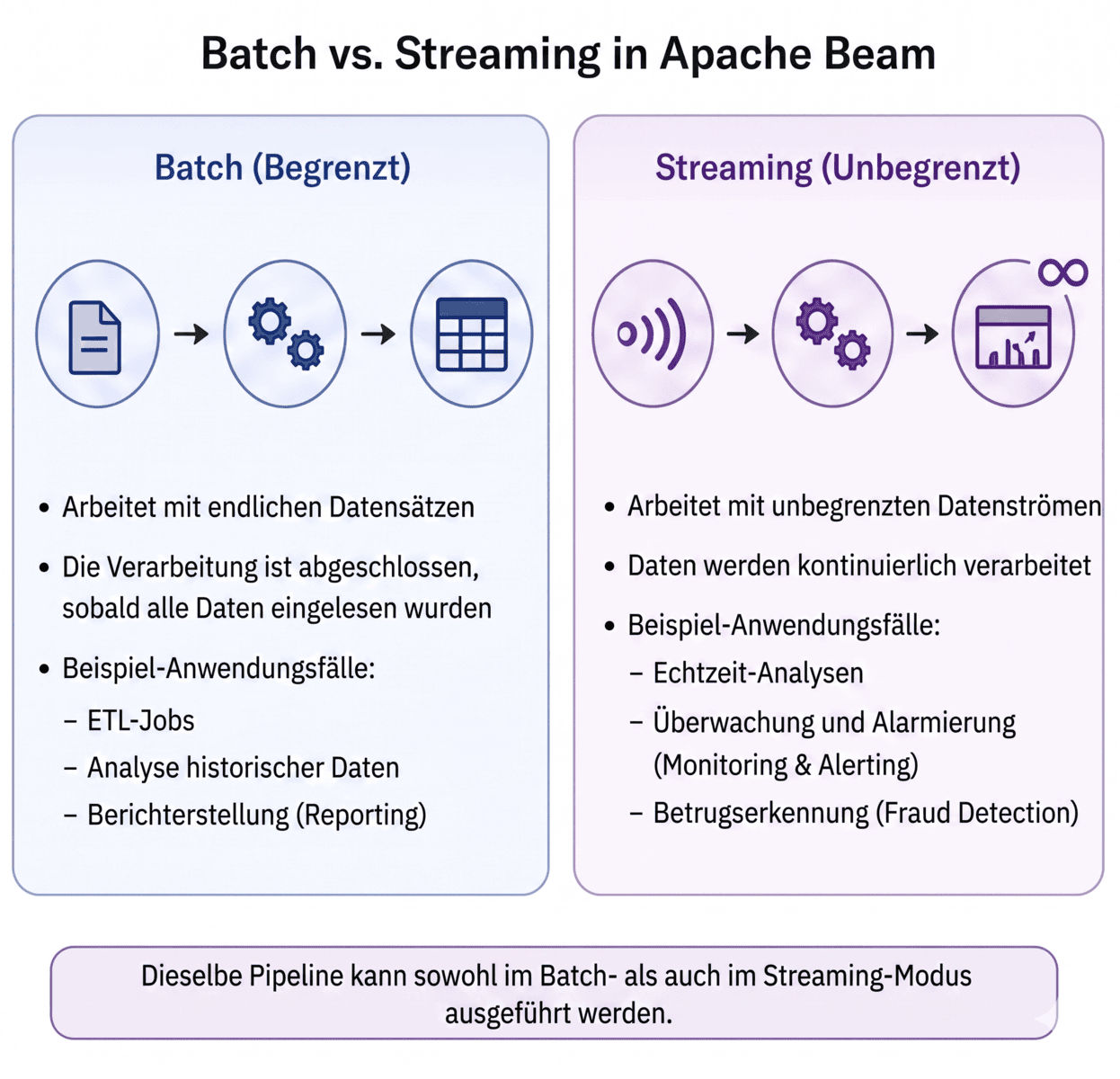
Batch vs. Streaming in Beam
Eines der mächtigsten Features von Beam ist die Fähigkeit, Batch- und Streaming-Verarbeitung als zwei Seiten derselben Medaille zu betrachten. Batch-Verarbeitung
- Arbeitet auf begrenzten (bounded) Datensätzen.
- Wird typischerweise für historische Analysen genutzt.
- Beispiel: Das Verarbeiten von Log-Dateien des letzten Monats.
Streaming-Verarbeitung
- Arbeitet auf unbegrenzten (unbounded) Datensätzen.
- Verarbeitet Daten quasi in Echtzeit.
- Beispiel: Das Monitoring von Live-Nutzeraktivitäten.
Das Modell von Beam erlaubt es dir, Pipelines zu schreiben, die nahtlos zwischen diesen Modi wechseln können. Das vermeidet doppelten Code-Aufwand und vereinfacht die Wartung massiv.
Windowing und Trigger
In Streaming-Systemen kommen Daten nicht immer in der richtigen Reihenfolge an. Apache Beam löst diese Herausforderung durch den geschickten Einsatz von Windowing und Triggern. Windowing Windowing unterteilt Daten basierend auf der Zeit in logische Häppchen. Zu den gängigen Window-Typen gehören:
- Fixed Windows (feststehende Zeitfenster, z. B. alle 5 Minuten)
- Sliding Windows (überlappende Intervalle)
- Session Windows (basierend auf Aktivitätslücken der Nutzer)
Trigger Trigger legen fest, wann die Ergebnisse eines Fensters ausgegeben werden sollen. Das ist besonders wichtig, um verspätet eintreffende Daten abzufangen und eine zeitnahe Ausgabe zu garantieren. Zusammen ermöglichen Windowing und Trigger eine präzise Kontrolle darüber, wie Streaming-Daten verarbeitet und bereitgestellt werden.
Unterstützte SDKs
Apache Beam bietet SDKs für mehrere Programmiersprachen an:
- Java (am ausgereiftesten)
- Python (weit verbreitet und aktiv weiterentwickelt)
- Go (wachsendes Ökosystem)
Jedes SDK erlaubt es Entwicklern, Pipelines mit vertrauten Sprachkonstrukten zu definieren und gleichzeitig das einheitliche Modell von Beam zu nutzen.
Wann solltest du Apache Beam einsetzen?
Apache Beam ist in den folgenden Szenarien besonders nützlich:
1. Echtzeit-Analysen
Wenn du Daten direkt bei ihrem Eintreffen verarbeiten und analysieren musst (z. B. bei der Überwachung des Nutzerverhaltens oder zur Betrugserkennung), sind die Streaming-Fähigkeiten von Beam extrem wertvoll.
2. ETL-Pipelines
Beam eignet sich hervorragend für ETL-Workflows (Extract, Transform, Load), vor allem wenn es um riesige Datensätze und komplexe Transformationen geht.
3. Ereignisgesteuerte Systeme
Anwendungen, die auf Event-Streams basieren – wie IoT-Systeme oder Microservices-Architekturen – profitieren massiv davon, wie Beam mit unbegrenzten Daten umgeht.
4. Plattformübergreifende Portabilität
Falls du dir die Flexibilität offenhalten willst, die Processing-Engine zu wechseln, ohne deine gesamte Pipeline neu schreiben zu müssen, bietet Beam eine starke Abstraktionsschicht.
Herausforderungen und Überlegungen
Obwohl Apache Beam viele Vorteile bietet, gibt es auch ein paar Hürden zu beachten.
- Lernkurve: Beam führt neue Konzepte wie Windowing, Watermarks und Trigger ein, die für Einsteiger durchaus komplex sein können.
- Debugging-Komplexität: Da Pipelines auf verteilten Systemen laufen, ist die Fehlersuche oft schwieriger als bei der lokalen Verarbeitung.
- Unterschiede zwischen den Runnern: Auch wenn Beam auf Portabilität setzt, unterstützen nicht alle Runner alle Features im gleichen Masse. Es ist wichtig, die Grenzen deines gewählten Runners zu kennen.
Apache Beam im modernen Data Stack
Apache Beam spielt eine Schlüsselrolle in modernen Datenarchitekturen. Es sitzt oft genau zwischen Ingestion-Systemen (wie Kafka) und Storage- bzw. Analyse-Systemen (wie BigQuery oder Data Lakes). Eine typische Architektur sieht meist so aus:
- Datenaufnahme via Message Queues oder APIs.
- Verarbeitung und Transformation mit Beam.
- Speicherung in Data Warehouses oder Data Lakes.
Das macht Beam zu einer leistungsstarken Komponente für den Aufbau skalierbarer End-to-End-Datenpipelines.
Fazit
Apache Beam bietet einen mächtigen und flexiblen Weg, um skalierbare Datenverarbeitungspipelines zu bauen. Durch die Vereinheitlichung von Batch und Streaming unter einem Dach vereinfacht es die Entwicklung und reduziert Redundanzen. Die Portabilität über mehrere Runner hinweg sorgt dafür, dass deine Pipelines zukunftssicher und anpassungsfähig bleiben. Sicher, es gibt eine gewisse Lernkurve – besonders bei den zeitbasierten Konzepten – aber für Teams, die mit grossen Datenmengen oder Echtzeit-Daten arbeiten, überwiegen die Vorteile die Komplexität bei Weitem. Wenn du moderne Datenpipelines baust und einen konsistenten, skalierbaren und portablen Ansatz suchst, solltest du dir Apache Beam definitiv mal anschauen.



