Jeder Mitarbeiter, der geschäftlich verreist, kennt das Gefühl: Du bist zurück am Schreibtisch, ein Stapel Quittungen wartet auf dich, und du musst alles manuell abtippen. Beschreibung der Ausgabe, Datum, Betrag und Währung – alles wird nacheinander eingegeben. Der Prozess ist zwar nicht kompliziert, aber eben extrem mühsam.
Da KI mittlerweile ein natürlicher Bestandteil moderner Software ist, war es noch nie so einfach, genau diese Art von kleinen, aber repetitiven Aufgaben zu automatisieren. Dieser Beitrag zeigt dir, wie du diese Reibungspunkte mit Spring AI und der Integration der Google Vertex AI API eliminierst.
Das Ergebnis ist ein Feature, das einfacher zu implementieren ist, als du vielleicht denkst. Und das vor allem eines tut: Nutzer begeistern.
Die versteckten Kosten der manuellen Ausgabenerfassung
Ein paar Minuten eines Arbeitstages für die Reisekostenabrechnung zu opfern, klingt erst einmal nicht nach einer Krise. Wenn man diese wenigen Minuten jedoch auf jeden Mitarbeiter und jede zweite Reise zu verschiedenen Events mehrmals im Monat hochrechnet, summiert sich das zu einer beachtlichen Menge an manueller Arbeitszeit.
Der Zeitverlust allein ist das eine. Viel schädlicher sind jedoch Effekte wie verspätete Einreichungen, die Mehraufwand für die Buchhaltung bedeuten. Zudem führen vergessene Belege zu fehlenden oder falschen Beträgen, und der allgemeine Frust sorgt für unterschwelligen Unmut aufseiten der Arbeitnehmer und Arbeitgeber.
In vielen Unternehmen ist die Brücke zwischen einem Papierbeleg und einem digitalen Datensatz immer noch eine Tabellenkalkulation oder verstreute PDFs. Die Mitarbeiter füllen eine Excel-Vorlage aus, hängen gescannte Belege an und schicken das Ganze per E-Mail an ihren Vorgesetzten oder die Buchhaltung. Jeden Monat die gleiche Datei, die gleichen Spalten, das gleiche Copy-and-Paste.
Selbst in Firmen, die bereits auf dedizierte Spesen-Software umgestiegen sind, bleibt das Kernproblem bestehen: Irgendjemand muss den Beleg immer noch lesen und die Daten manuell eingeben. Die Software hat zwar den Genehmigungsworkflow digitalisiert, aber nicht den Schritt der manuellen Dateneingabe.
Die Frage ist also: Kann moderne KI das mit minimalem Aufwand lösen? Wie sich herausstellt, ja – und die Implementierung ist simpler, als die meisten Entwickler vermuten.
Die Wahl des Stacks
Das in diesem Beitrag beschriebene Feature wurde entwickelt für «Hello Today», dem All-in-One ERP von N47 für Dienstleister. Das Ziel war nicht, ein eigenständiges KI-Produkt zu bauen, sondern den bestehenden Workflow für Ausgaben um eine gezielte Integration zu erweitern, die genau diesen einen Reibungspunkt für die Nutzer beseitigt.
Die Integration nutzt Gemini 2.5 Flash über die Google Vertex AI, eingebunden via Spring AI. Das Modell bietet einen exzellenten Kompromiss zwischen Performance und Kosten und arbeitet bei der Extraktion strukturierter Daten aus Dokumenten extrem zuverlässig. Da es nativ multimodal ist, liest es Texte direkt aus Bildern, ohne dass ein weiterer Schritt im Voraus nötig wäre. Das ist besonders wichtig für ein Feature, das jedes Format verarbeiten muss, das ein Nutzer hochladen könnte: ein Handyfoto, eine PDF-Rechnung oder ein gescanntes Dokument.
Zusätzlich bietet Spring AI durch das ChatModel-Interface eine saubere Abstraktionsebene über die verschiedenen Modellanbieter. Welches Modell im Hintergrund läuft, ist eine reine Konfigurationssache und keine Frage des Codes. Das bedeutet, dass es in Zukunft problemlos ausgetauscht werden kann, ohne die Integrationslogik anzufassen, sollte ein noch passenderes Modell auf den Markt kommen.
Einrichten der Integration
Das Gesamtprojekt basiert auf Spring Boot und Maven. Um Vertex AI ordnungsgemäss in das Projekt zu integrieren, müssen wir die folgende Library-Dependency in der pom.xml ergänzen, damit wir die API im Service Layer nutzen können:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-vertex-ai-gemini</artifactId>
</dependency>Um das Setup abzuschliessen, ist eine separate Konfiguration innerhalb der application.yml-Datei erforderlich.
spring:
ai:
vertex:
ai:
gemini:
project-id: ${GCP_PROJECT_ID}
location: ${GCP_LOCATION:europe-west1}
transport: restDie Umgebungsvariablen GCP_PROJECT_ID und GCP_LOCATION verweisen auf das unternehmensinterne Gemini-Deployment, damit deine Daten sicher innerhalb der GCP-Umgebung der Organisation bleiben. Das ist besonders wichtig, da Spesenquittungen ja durchaus sensible Nutzerdaten enthalten können.
Spring AI konfiguriert die VertexAiGeminiChatModel-Bean automatisch anhand dieser Eigenschaften, sodass du dich gar nicht erst mit der Initialisierung des Clients oder unnötigem Boilerplate-Code herumschlagen musst.
Dateityp-Erkennung
Bevor du irgendwelche Daten an Gemini sendest, muss das Modell erst einmal den MIME-Typ der Datei korrekt identifizieren, damit es überhaupt sinnvolle Informationen zurückgeben kann. Über den Service-Layer und das Setup können Nutzer beliebige Fotos, PDFs oder andere Dateien hochladen, welche die Quittung enthalten und als Byte-Array (byte[] fileData) gespeichert werden. Um nun präzise zu erkennen, was diese Bytes ursprünglich eigentlich dargestellt haben, nutzen wir eine externe Bibliothek namens Apache Tika. Diese liest die Rohdaten direkt aus:
private Media detectAndCreateMedia(byte[] fileData) {
Tika tika = new Tika();
String detectedMimeType = tika.detect(fileData);
MimeType mimeType = MimeTypeUtils.parseMimeType(detectedMimeType);
return new Media(mimeType, new ByteArrayResource(fileData));
}Das Ergebnis ist dann ein Media-Objekt, das die Dateien innerhalb von Spring AI an den Prompt anhängt und dabei die korrekten Typ-Metadaten beibehält. So erhält Gemini die Datei und weiss ganz genau, was es da eigentlich vor sich hat, um die Quittung anschliessend sauber zu entziffern.
Modell-Konfiguration
Den Modellaufruf selbst zu gestalten, ist ziemlich geradlinig, sofern du zwei wichtige Entscheidungen im Hinterkopf behältst. Die erste betrifft die Variable „Temperature“:
VertexAiGeminiChatOptions options = VertexAiGeminiChatOptions.builder()
.model("gemini-2.5-flash")
.temperature(0.0d)
.maxOutputTokens(2048)
.build();Mit einer Temperature von 0.0 eliminierst du jegliche Zufälligkeit. Da es sich hier um eine Extraktionsaufgabe und nicht um ein kreatives Projekt handelt, muss der Output bei jeder Ausführung des Prompts konsistent und maschinenlesbar bleiben. Diese einzelne Einstellung ist tatsächlich die wichtigste Konfigurationsentscheidung für diesen Anwendungsfall.
Die zweite Entscheidung betrifft die asynchrone Ausführung. Der Aufruf selbst nutzt ein sogenanntes CompletableFuture, damit der Prozess nicht blockiert, während das Modell seine Reasoning-Schritte durchläuft:
return CompletableFuture.supplyAsync(() -> {
Prompt prompt = new Prompt(userMessage, options);
ChatResponse response = chatModel.call(prompt);
return response.getResult().getOutput().getText();
});Sowohl die Textinstruktionen als auch die Rohdateien werden zusammen in einer einzigen UserMessage übermittelt. Gemini erhält also alles in einem gemeinsamen multimodalen Request und wertet die Informationen simultan aus.
Prompt Engineering
Die Modell-Integration ist zwar geradlinig, aber die eigentliche Arbeit steckt im Prompt. Das übergeordnete Ziel dabei ist, Gemini wie einen deterministischen API-Endpunkt agieren zu lassen und nicht wie einen Chat-Assistenten. Das fängt schon beim Framing an:
Du bist eine API zur Datenextraktion. Dein Output wird direkt von einer Maschine geparst.
Dieses Framing allein reduziert unerwünschtes Verhalten wie etwa Markdown-Wrapper, erklärenden Text oder in Code-Blöcke eingebettetes JSON bereits drastisch. Je nachdem, wie viele Dateien du hochlädst, wählt der Service eine von zwei Prompt-Varianten aus. Bei einer einzelnen Quittung definiert der Prompt das Output-Schema explizit:
Extract data into a JSON object with the exact following keys:
{
"name": "The merchant or vendor name.
Do NOT extract the customer/payer name.",
"description": "A short summary of items purchased.
If there are 5 or fewer items, list them with
quantities (e.g. '2x Coffee'). If there are MORE
than 5, summarize by category instead.",
"dateOfExpense": "The date on the receipt (YYYY-MM-DD).
If unknown, return empty string.",
"price": The total amount (float),
"currency": The 3-letter ISO currency code (e.g. CHF, USD, EUR).
}Wenn du mehrere Dateien für dieselbe Reise hochlädst, weist eine zweite Variante Gemini an, die Daten zu aggregieren, statt sie nur zu extrahieren. Anstatt für jede Datei einen eigenen Eintrag zurückzugeben, erstellt das Modell eine einzige, kohärente Zusammenfassung. Ein Beispiel: Aus einem Zugticket, einer Hotelrechnung und einem Beleg vom Abendessen wird „Reise nach Zürich“ mit einem Gesamttotal. Die Struktur des zurückgegebenen JSON bleibt dabei identisch, lediglich die Anweisungen ändern sich.
Beide Varianten enthalten einen RULES-Block, um das Ausgabeformat strikt zu erzwingen:
RULES:
1. "dateOfExpense" MUST be in
strict ISO-8601 format (YYYY-MM-DD).
2. "price" must be a number — no currency symbols.
3. Return ONLY a valid, raw JSON string.
4. Do NOT use Markdown formatting.
5. Do NOT include any conversational text.
Start with { and end with }.
6. Detect the language of the document and
write "name" and "description" in that SAME language.Regel 6 ist eine einzelne Zeile, die einen erheblichen UX-Vorteil bietet – und das ganz ohne zusätzlichen Code. Ein deutscher Beleg liefert automatisch eine deutsche Beschreibung und eine französische Rechnung französischen Text zurück, ohne dass du irgendwo in der Anwendung eine zusätzliche Übersetzungslogik implementieren musst.
Edge Cases
Nicht jeder Beleg kommt in perfektem Zustand an. Ein paar Edge Cases haben die finale Implementierung massgeblich geprägt:
Leere oder unlesbare Dateien werden abgefangen, noch bevor das Modell überhaupt aufgerufen wird. Wenn alle angegebenen Datei-IDs zu leerem Inhalt führen, bricht der Request sofort mit einer klaren Fehlermeldung ab. Ein Modell ohne Daten aufzurufen, ergibt schlicht keinen Sinn und verschwendet nur unnötig Tokens.
Unbekannte Daten stellten ein subtileres Problem dar. In frühen Versionen wurde Gemini angewiesen, auf das heutige Datum zurückzugreifen, falls kein Datum gefunden werden konnte. Mittlerweile ersetzt ein leerer String diesen Wert. Ein halluziniertes Datum, das plausibel aussieht, ist weitaus schlimmer als ein leeres Feld, das der Nutzer selbst ausfüllt – schliesslich könnten sonst unbemerkt falsche Daten einfliessen.
Falls Gemini schliesslich eine Antwort liefert, die sich nicht in die erwartete Struktur deserialisieren lässt, wird ein leeres Objekt zurückgegeben, anstatt einen 500er-Fehler auszugeben. Der Nutzer verliert zwar die Option der automatischen Vorausfüllung, kann die Ausgabe aber immer noch manuell erfassen.
Ergebnisse und Beispiele
Um das Ganze konkret zu machen, schauen wir uns den Upload eines einzelnen Belegs an. Ein Nutzer fotografiert die Quittung eines Aufenthalts im Hilton Hotel nach einem Kundenevent in San Francisco – auf Englisch, datiert auf den 20. November 2019, über einen Gesamtbetrag von 828,72 $. Der Beispiel-Beleg wurde mit Receipt Faker erstellt. Hier ist das rohe JSON, das Gemini erfolgreich daraus extrahiert hat:
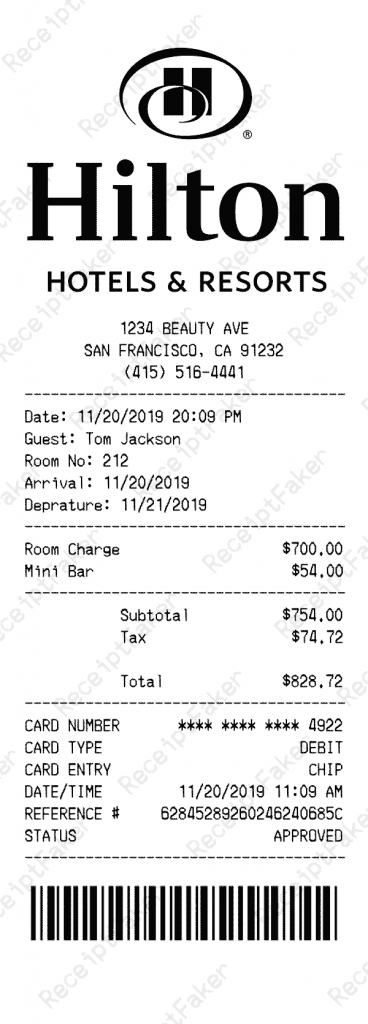
"data": {
"extractExpenseData": {
"name": "Hilton HOTELS & RESORTS",
"description": "Room Charge, Mini Bar in San Francisco",
"dateOfExpense": "2019-11-20",
"price": 828.72,
"currency": "USD",
"__typename": "ExtractExpenseDataResponse"
}
}Die Beschreibung wird automatisch auf Englisch ausgegeben, passend zur Quelle des Dokuments, ohne dass eine Locale-Konfiguration erforderlich ist. Die Antwort erfolgt ziemlich schnell und ist in jedem Datenpunkt korrekt.
Modell-Robustheit
Die berechtigte Frage lautet, wie zuverlässig Gemini mit realen Dokumenten umgeht, da diese in ihrer Qualität variieren und verblassten Text, schlechte Lichtverhältnisse oder sogar Handschrift aufweisen können. In Tests hielt das Modell deutlich besser stand als erwartet.
Ein besonders beeindruckendes Beispiel: ein handschriftlicher Beleg aus den frühen 1990er Jahren mit Beträgen in «Deutsche Mark». Gemini hat ihn korrekt gelesen, die Gesamtsumme extrahiert und DM als Währung identifiziert, obwohl die Deutsche Mark seit 2002 nicht mehr im Umlauf ist. Das Modell hat weder geraten noch ein modernes Äquivalent halluziniert.
Für ein Feature, das auf einem Modell läuft, das innerhalb der Gemini-Reihe als Leichtgewicht gilt, ist dieses Mass an Robustheit über Dokumentenalter, Qualität und Format hinweg wirklich beeindruckend. Das bedeutet, dass die Funktion ohne jegliche Vorverarbeitung oder Qualitätsprüfung der hochgeladenen Dateien zuverlässig funktioniert.
Auswirkung in der «Real world»
Die komplette Integration, einschliesslich der Service-Methoden, DTOs, GraphQL-Schemas und Tests, umfasst etwa 200 Zeilen Code. Der Grossteil der Intelligenz steckt im Prompt und in Gemini selbst.
Das Feedback der Nutzer war durchweg positiv. Die Extraktion von Ausgaben ist eine der Funktionen, die Nutzer von sich aus ansprechen, weil sie etwas wirklich Nerviges aus ihrem Arbeitsalltag entfernt hat.
Die übergeordnete Lektion ist es wert, deutlich ausgesprochen zu werden: KI-Mehrwert erfordert kein eigenständiges KI-Produkt. Eine präzise abgegrenzte Integration mit einem leistungsfähigen Modell kann echte Reibungspunkte aus einem realen Workflow entfernen – und das mit einem Bruchteil des Aufwands, den eine dedizierte Pipeline zur Dokumentenverarbeitung erfordern würde. Der Schlüssel liegt darin, das richtige Problem zu identifizieren: Die Umwandlung repetitiver manueller Arbeit in einen automatisierten Prozess.
Fazit
Die manuelle Erfassung von Ausgaben ist mühsam, fehleranfällig und absolut lösbar. Eine gezielte Integration mit einem recht einfachen Gemini-Modell 2.5 Flash und Spring AI kann den Schritt der Datenextraktion mit minimalem Code automatisieren und liefert out-of-the-box überraschend gute Ergebnisse, wobei eine breite Palette an Dokumententypen und -zuständen unterstützt wird.
Die Erweiterung der Funktion ist weitgehend eine Frage der Anpassung des Prompts – etwa für die Aggregation mehrerer Dateien, automatische Spracherkennung oder sogar Währungsumrechnung zum aktuellen Wechselkurs.
Der schwierigste Teil der gesamten Implementierung ist das Schreiben eines Prompts, der konsistent maschinenlesbaren Output liefert. Sobald dieser steht, fügt sich der Rest schnell zusammen.
Kontakt aufnehmen
Wenn du darüber nachdenkst, wo KI einen ähnlichen Reibungspunkt in deinem Produkt beseitigen könnte, melde dich bei uns – wir freuen uns darauf, von deinem aktuellen Ansatz zu hören oder dir dabei zu helfen, den richtigen Weg zu finden.



