Einleitung
Ein Feature funktioniert im Staging-Bereich perfekt. Die KI hat die Kernimplementierung in wenigen Minuten generiert, die Unit-Tests liefen glatt durch und die API antwortete mit sauberen 200-OK-Statusmeldungen.
Dann kam der Go-Live.
Ein nicht abgefangener Edge Case tauchte auf. Eine alte, undokumentierte, aber geschäftskritische Logik wurde verletzt. Eine Upstream-Integration verhielt sich unter Last plötzlich minimal anders. Und auf einmal konnte der Code, der perfekt wirkte, das eigentliche Problem nicht mehr lösen.
Dieses Szenario spielt sich derzeit weltweit in Entwicklerteams ab. KI-Codierungsassistenten haben das Generieren von Boilerplate, das Konfigurieren von Endpunkten und das Schreiben von Syntax quasi augenblicklich machbar gemacht. Auf den ersten Blick fühlt sich das nach einem absoluten Produktivitätsgewinn an.
Doch während die Deployment-Geschwindigkeit steigt, erkennen Engineering Leader eine tieferliegende Wahrheit: Das Schreiben von Code war nie der Flaschenhals. Zu verstehen, was genau gebaut werden muss, ist es.
KI schreibt schnell, die Realität bewegt sich langsamer
Um zu verstehen, warum diese Lücke existiert, schauen wir uns mal einen Standard-Prompt an: „Erstelle einen Spring Boot REST-Endpunkt mit Token-Validierung und CRUD-Operationen.“
In Sekundenschnelle liefert ein KI-Assistent sauberen, syntaktisch korrekten Code. Das ist beeindruckend! Allerdings agieren Produktivsysteme nicht in isolierten Code-Snippets. Sie existieren in einem komplexen Geflecht aus:
- Architektonischen Einschränkungen: Bestehende Datenmodelle, Microservice-Grenzen und Latenzbudgets.
- Organisatorischer Historie: Frühere Entscheidungen und technische Schulden, die bestimmen, warum ein System sich genau so verhält.
- Impliziter Business-Logik: Die ungeschriebenen Regeln, die Produktmanager und Fachexperten im Kopf haben, statt in der Dokumentation.
KI kann zwar Code generieren, aber sie kann deine organisatorische Realität nicht automatisch ableiten. Wenn Teams die Code-Produktion beschleunigen, ohne dass das gemeinsame Verständnis im gleichen Masse mitwächst, bauen sie nicht einfach nur schneller; sie schaffen im grossen Stil technische Schulden, fragile Integrationen und am Bedarf vorbei entwickelte Features.
Code-Generierung ist mittlerweile ein gelöstes Problem. Kontext-Generierung ist die neue Herausforderung.

Why Code Was Never the Bottleneck
Jahrzehntelang wurde die Effizienz in der Softwareentwicklung daran gemessen, wie schnell Entwickler Ideen in Syntax verwandeln konnten. Teams optimierten ihre taktische Geschwindigkeit: Sie meisterten Tastaturkurzbefehle, lernten Framework-APIs auswendig und verinnerlichten die Nuancen bestimmter Programmiersprachen.
Das Wissen war im Kopf des Entwicklers gespeichert, weil der physische Akt des Codeschreibens der eigentliche Engpass war.
Heute hat KI dieses Paradigma verschoben. Moderne Assistenten übernehmen die mechanische Arbeit, generieren Boilerplate, schlagen Implementierungen vor und beschleunigen repetitive Aufgaben in Sekundenschnelle. Doch genau diese Automatisierung hat eine tiefere Realität offengelegt: Das Tippen von Code war lediglich der letzte Schritt in einem viel grösseren kognitiven Prozess.
Tools tun sich nach wie vor schwer damit, die Elemente zu erfassen, die Software Engineering eigentlich ausmachen:
- Intent: Das ultimative geschäftliche Ziel hinter einem Feature.
- System History: Warum ein Legacy-Workaround vor drei Jahren genau so implementiert wurde.
- Widersprüchliche Constraints: Die Balance zwischen strenger Security-Compliance und aggressiven Latenzanforderungen.
Wenn wir Softwareentwicklung als reines Syntaxproblem betrachten, sieht der Code genau so lange korrekt aus, bis er in der Production-Umgebung landet. Die Production führt uns drastisch vor Augen, dass Enterprise-Software selten in sauberen, isolierten Beispielen entsteht.
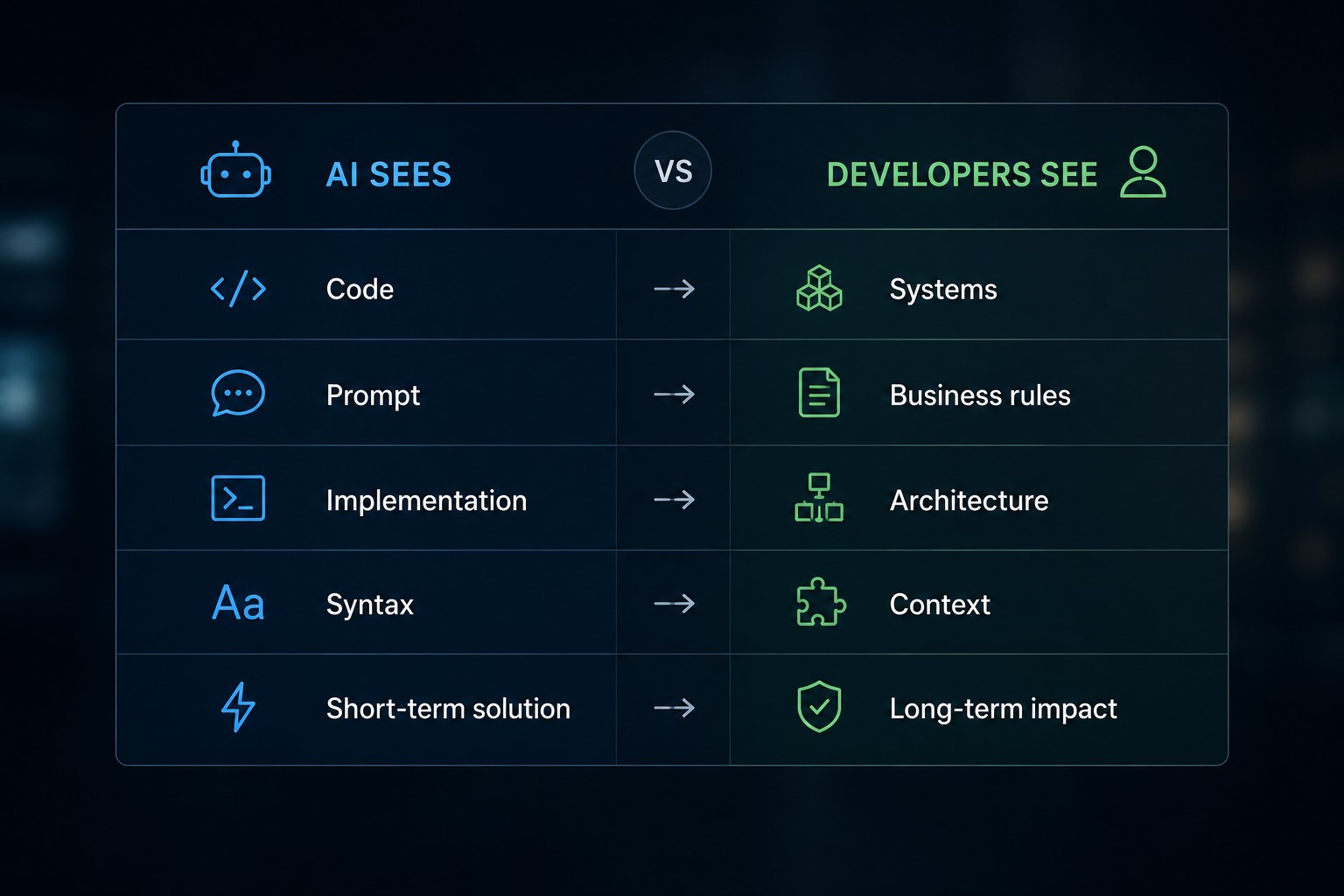
Der Wandel vom Prompting zum Context Engineering
Vor nicht allzu langer Zeit lag der Fokus der Branche fast ausschliesslich auf dem «Prompt Engineering» – also auf der spezifischen Formulierung, Struktur und Formatierung, mit der man einem LLM das gewünschte Ergebnis entlocken wollte.
Doch eine perfekte Syntax kann fehlerhafte Annahmen nicht wettmachen. Selbst der brillanteste Prompt kompensiert weder eine fehlende geschäftliche Anforderung noch eine unberücksichtigte Abhängigkeit. Genau das stösst gerade einen grundlegenden Wandel an: weg vom Prompt Engineering, hin zum Context Engineering.
| Was | Prompt Engineering | Context Engineering |
| Ziel | Optimierung einzelner Abfragen hinsichtlich der Syntax. | Die Abstimmung von KI auf Architektur, Geschäftsziele und Rahmenbedingungen. |
| Input | Einzelne Anweisungen und Formatierungsregeln. | Strukturierte Systemhistorie, Datenschemata und Domänenlogik. |
| Ergebnis | Funktionsfähige Code-Blöcke. | Eine nahtlose, produktionsreife Systemintegration. |
Die zentrale Herausforderung besteht längst nicht mehr darin, der KI bessere Fragen zu stellen. Vielmehr geht es darum, technische Umgebungen und Dokumentations-Frameworks so aufzubauen, dass die KI Zugriff auf genau denselben Kontext erhält, auf den sich auch ein erfahrener Staff Engineer verlässt. Die KI scheitert schliesslich selten an der Syntax – sie scheitert an der Isolation.

Was das für Tech-Leader bedeutet
Für IT-Entscheider und Produktmanager verändert dieser Wandel grundlegend, wie Team-Geschwindigkeit und technische Stabilität bewertet werden müssen. Um KI sinnvoll zu nutzen, ohne systemische Komplexität zu erzeugen, müssen Unternehmen auf drei wesentliche Säulen setzen:
- Fokus auf den Business-Intent: Produktmanager müssen das Warum und das Was absolut präzise auf den Punkt bringen. Wenn die Business-Logik unklar ist, schreibt die KI den falschen Code einfach nur in Rekordzeit.
- Architektur vor Syntax stellen: Da das reine Coden austauschbar wird, schützt dich eine saubere Architektur vor der Fragmentierung deines Systems. Erfahrene Entwickler sind wichtiger denn je – nicht um Code zu tippen, sondern um das Systemdesign zu sichern.
- Explizit dokumentieren, nicht implizit: KI glänzt erst durch gut strukturierte Daten. Aktuelle Dokumentationen, saubere APIs und unmissverständliche Business-Anforderungen sind keine Nebensache mehr, sondern der Treibstoff für deine Automatisierungstools.
Der strategische Vorteil: Klarheit
Programmiersprachen verschwinden nicht, und Entwickler tun es auch nicht. Die Art der technischen Hebelwirkung hat sich jedoch verändert.
KI wirkt wie ein Verstärker, nicht wie ein Ersatz. Sie skaliert den aktuellen Reifegrad deiner Entwicklung. Wenn deine Architektur bröckelt und deine Business-Logik schwammig ist, skaliert die KI genau dieses Chaos. Wenn dein Kontext dagegen messerscharf und deine Systemgrenzen sauber definiert sind, skaliert die KI deine Umsetzung.
Am Ende verschiebt sich der Wettbewerbsvorteil. Die Entwicklungsteams, die das Rennen machen, werden nicht diejenigen sein, die die meisten Zeilen Code produzieren. Es werden die sein, die das klarste Verständnis für die Probleme behalten, die sie eigentlich lösen wollen.
Wie passt sich dein Team dem Wandel von der Codegenerierung zum Kontextmanagement an?
Bei N47 helfen wir Unternehmen dabei, die starken architektonischen Grundlagen und Engineering-Praktiken aufzubauen, die man braucht, um die Entwicklungsgeschwindigkeit sicher zu steigern. Lass uns doch mal besprechen, wie wir deinen Systemkontext für die nächste Entwicklungsgeneration optimieren können.



