WHY DO WE NEED RECOMMENDATION SYSTEMS?
Walking through the steps of technology, which has rapid growth nowadays, represents a huge challenge for humanity. Software systems are currently creating a dynamic world, which undoubtedly facilitates human life and enables its improvement to the highest point of a digital being.
Many mobile and web systems offer easy usage and search through the internet. They are a necessary segment of education, health, employment, trade and of course fun. In such a fast and dynamic life, it is necessary to have more and more systems that will help us enable fast recommendation search when in need of finding relevant information, all in order to save us time. Usually, generated recommendation systems are according to the collaboration filtering algorithms or content-based methods.
RECOMMENDATION SYSTEMS IN REAL LIFE
In real life, people are overwhelmed with making a lot of decisions, no matter of its importance, either minor or major. Understanding human choices is a field studied by cognitive psychology.
One of the most important factors influencing the decisions an individual makes is ‘the past experience’, i.e. the decisions made by the man in the past, affect those he will make in the future.
Human actions are also dependent on the experiences they have gained in interactions with other people. The opinion of others affects our lives without us being aware of it. Relationship with friends affects what neighbourhood we will live in, which place we will visit during our vacation, in which bar we will have a drink, etc.

If one person has positive experiences with another one, then he/she has gained trust and authority over the particular individual and is more likely to follow their advice, as well as choosing the decisions that the person chose when they were in a similar situation.
RECOMMENDATION SYSTEMS IN THE DIGITAL WORLD
All large companies and complex systems use collaborative filtering, as an example of this is the social network “Facebook” with the phrase “People you may know”. Facebook is a hugely complex system and has a massive database, which is why they have a need for an optimization of the user data set so that they can provide a precise recommendation. They also have collaborating systems for the news feed, as well as for the game, fun pages, groups, and event sections.
Another, well-known technology and media service provider which uses those collaboration systems is Netflix, with the “Because you watched” phrase. Netflix uses algorithms and machine learning, probably based on genres, history of the watched movies, ratings and the amount of all ratings of the users that have a similar content taste as ours.
Here is as well Amazon, the multinational technology company, which uses the algorithms for a product recommendation for their clients. They use the item-to-item approach for the recommendation.
Last example but not least, is the most successful business social network LinkedIn, which uses ex. “People in the Information Technology & Services industry you may know”, “People you may know from Faculty XXX”, “Trending pages in your network”, “Online events for you” and a number of other phrases.
I made a research on the collaborative filtering algorithm, so I will deeply explain how this algorithm works, please read the analysis in the sections below.
RECOMMENDATION SYSTEM AND COLLABORATIVE FILTERING
Based on the selected data processing algorithm, the systems use different recommendation techniques.
Content-based system
People who liked this also likes that as well

Collaborative filtering
Analyzing a huge amount of information

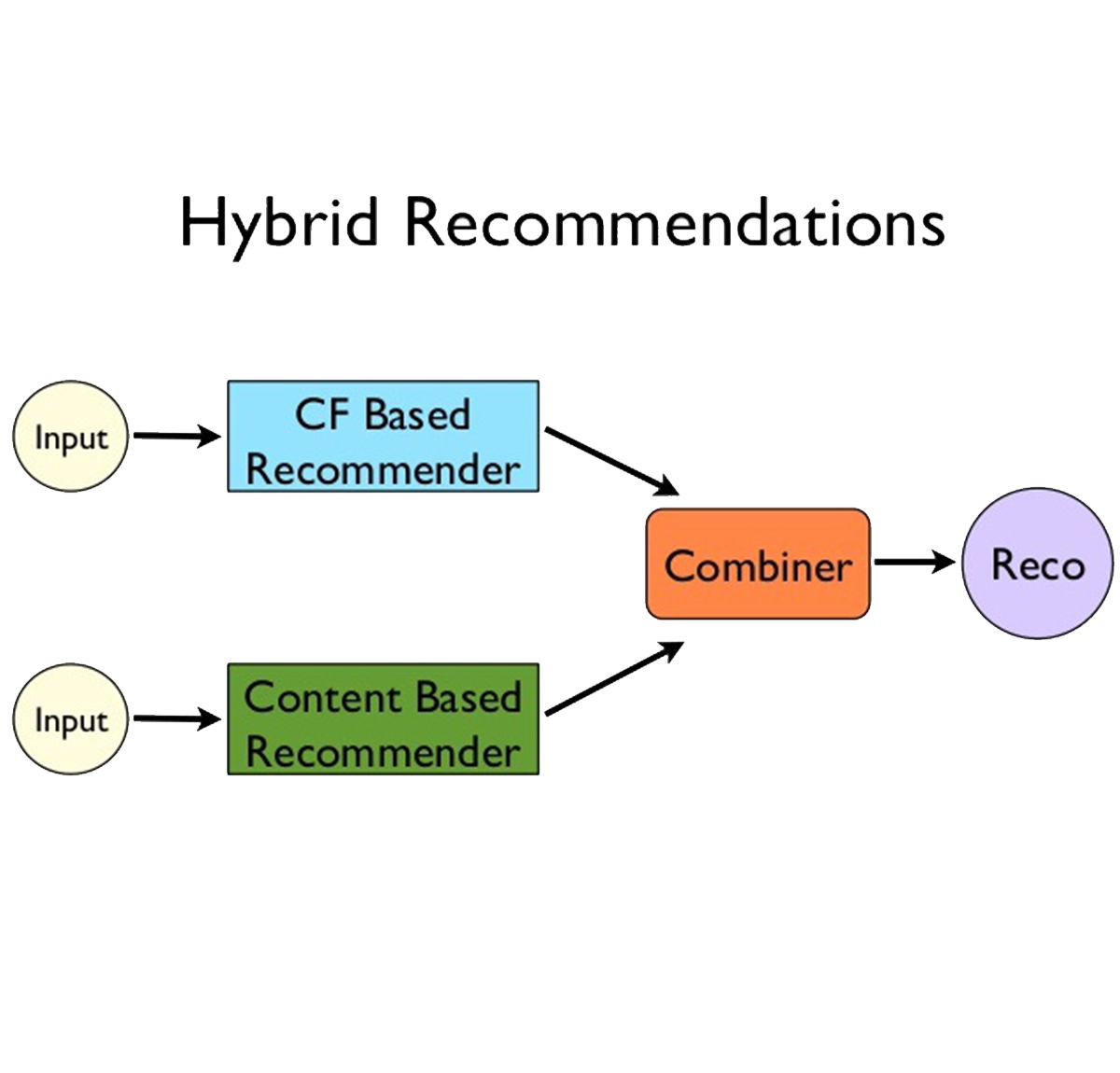
Hybrid recommendation systems
COLLABORATIVE FILTERING – DETAILED ANALYSIS
On a coordinate system, we can show the popularity of products, as well as the number of orders.
The X-axis is presenting the product curve, which shows the popularity of a variety of products. The most popular product is on the left part – at the head of the tail, and the less popular ones are in the right part. Under popularity, I mean how many times the product has been ordered, and viewed by others.
The Y-axis is representing the number of orders and product overviews over a certain time interval.
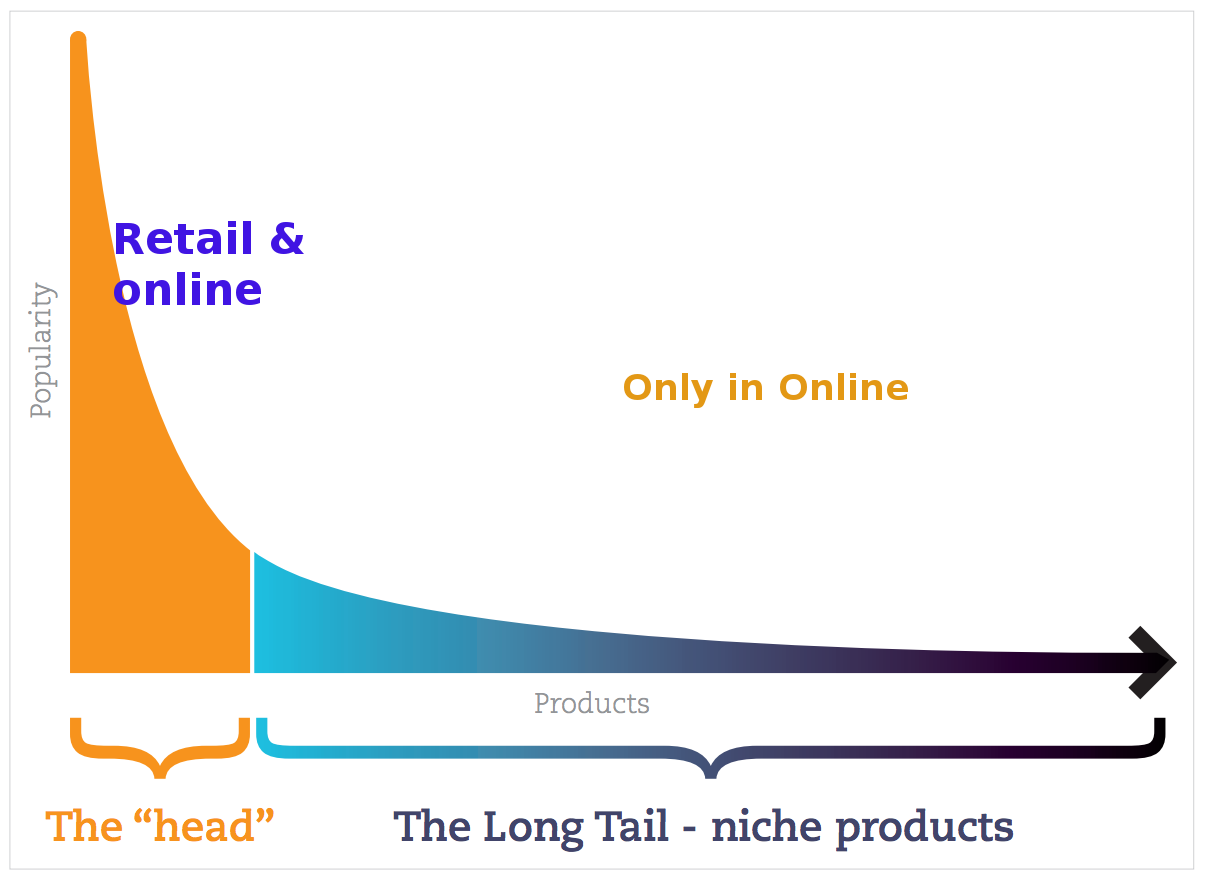
By analyzing the curve, it is noticeable that the often ordered products usually are considered most popular, and those that have not been ordered recently are omitted. That is what the collaborative filtering algorithm offers.
A measure of similarity is how similar two data objects are to each other. The measure of similarity in a dataset usually described as distance with dimensions, which represent characteristics of the objects that are in comparison. If the distance is small, then the degree of similarity is large, and vice versa. The similarities are very subjective and highly dependent on the domain of the systems.
The similarities are in the range of 0 to 1 [0, 1].
Two main similarities:
- Similarity = 1 if X = Y
- Similarity = 0 if X != Y
Collaborative filtering is processing the similarity of the data we have, with the help of several theorems, such as Cosine similarity, Euclidean Distance, Manhattan distance etc.

COLLABORATIVE FILTERING – COSINE SIMILARITY
In the beginning, we need to have a database and characteristics of the items.
For cosine similarity implementation, we need a matrix of similarity from the user database. In this matrix, the vector A are the products, and vector B are the users. Matrix is in format AXB. The fields of the matrix represent the grade/rating of the users’ Ai over the products Bj.
Therefore, we can imagine that we have users from 1 to n {1, …n} and grades/ratings on the products {1,…10}. Every row represents a different user, and every column represents one product. Every field of the matrix consists of the product grade/rating that the user has entered. Now, with this generated matrix, we can use the formula for finding the similarity between the users:

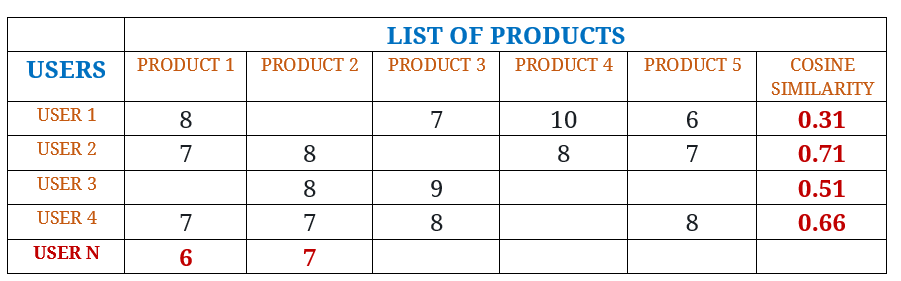
STEP 1:
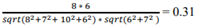
Similarity (UserN, User1) =
STEP 2:
In step 1, we can see that User N has the most similarities with User 2, but we can see that in the data we have a deficiency for some product ratings, so we should count the priority of the products that User N, has not set a rating. Now we need the values for the most similar users with User N, and those are User 2 and User 4. The following formula should be used:
Priority (product) = User2 (value*similarity) + User4 (value*similarity).
Example:
Priority(product3) = 8 * 0.66 = 5.28
Priority(product4) = 8 * 0.71 = 5.68
Priority(product5) = 7 * 0.71 + 8 * 0.66 = 10.25
STEP 3:
If we want to recommend two products to User N, these will be product5 and product4.
CONCLUSION:
Similarity theorems have their advantages and disadvantages, depending on what data set they apply. From the above analysis, we came to a conclusion that if the data contains zero values and are rarely distributed, we use the metric for computed a cosine similarity that handles nonzero values. Otherwise, if the data are densely distributed and diversity instead of similarity of users/products, and we have non-zero values, then we use the measures for calculating Euclidean distance. Such systems are under constant pressure from large volumes of data in databases and will undergo to even more challenges due to the daily increasing volume of the data. Therefore, there is a growing need for such new technologies that will dramatically improve the scalability of the recommendation systems.
QUESTION: WHAT WILL HAPPEN IN THE FUTURE?
ANSWER: ONLY TIME WILL TELL.



