ArchitectureJavaMultithreadingSpring BootThread synchronization Java multithreading: synchronizing code blocks by value of Object
ArchitectureJavaSpring Boot Microservice architecture: Using Java thread locals and Tomcat/Spring capabilities for automated information propagation
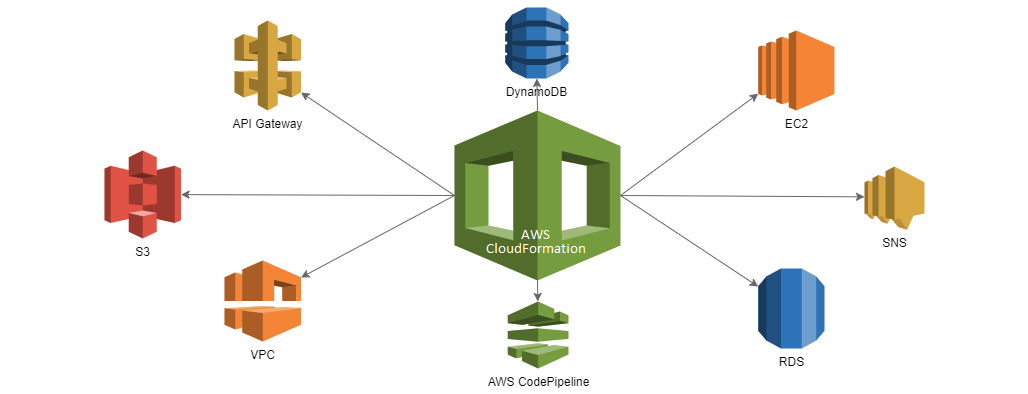
ArchitectureAutomationAWSAWS CloudFormationCI/CDInfrastructure CloudFormation: Passing values and parameters to nested stacks
AndroidArchitectureMethodology The practical guide: Refactor android application to follow the MVP design pattern
ArchitectureConferenceEducationJavaShowcaseSpring BootTechnology Spring Cloud Stream (event-driven microservice) with Apache Kafka… in 15 Minutes!
ArchitectureCI/CDConferenceCultureEducationEventsJavaScriptTechnologyVue.js FrontCon 2019 in Riga, Latvia
ArchitectureCI/CDConferenceEducationJavaSpring BootTechnology Voxxed Days Bucharest & Devoxx Ukraine – HERE WE COME!
Hi there Daniel, thanks for raising that question. Well, you can achieve better security by putting the master password as…
Promanage IT Solutions has emerged as one of the most popular WordPress Development services in a short time. We have…
Hi Jovan, If you store the jasypt.encryptor.password in your propertyfile together with the encrypted passwords, anyone who gets access to…















Налаженный бизнес или успешная франшиза? Рейтинг франшиз
Technically, static volatile fetches the value from "main memory" instead of local cache, isn't it?
Hi there Daniel, thanks for raising that question. Well, you can achieve better security by putting the master password as…
Promanage IT Solutions has emerged as one of the most popular WordPress Development services in a short time. We have…
Hi Jovan, If you store the jasypt.encryptor.password in your propertyfile together with the encrypted passwords, anyone who gets access to…