- The Infrastructure Gap Nobody Talks About
- What Is an LLM Proxy, Actually?
- Why This Problem Is Urgent Right Now
- Core Capabilities of a Production-Grade LLM Proxy
- Security Architecture: Defense-in-Depth for AI Systems
- Governance: From Experimental Tool to Managed System
- The Honest Trade-offs
- Where This Is Going
The Infrastructure Gap Nobody Talks About
Enterprise AI has crossed a threshold. What started as isolated experiments with ChatGPT integrations and proof-of-concept chatbots has matured into production-grade deployments: customer-facing support agents, internal developer copilots, real-time analytics pipelines, and increasingly, autonomous multi-agent workflows.
But here’s the uncomfortable truth most engineering teams discover the hard way: scaling LLM usage without a control layer is a ticking clock. You end up accumulating fragmented API integrations, unpredictable token costs, security blind spots, and a compliance posture that auditors will not enjoy reviewing.
The solution isn’t more tooling on the application layer. It’s a dedicated middleware layer sitting between your applications and your AI providers, what the industry is calling an LLM proxy. For any organization running AI in production, this isn’t a nice-to-have. It’s foundational infrastructure.
What Is an LLM Proxy, Actually?
An LLM proxy is a centralized gateway that mediates all traffic between your applications and one or more LLM providers: OpenAI, Anthropic, Google Gemini, local models, whatever your stack includes.
Instead of every service maintaining its own direct integration with individual provider APIs, all requests flow through a single controlled endpoint. The proxy then handles authentication, request formatting, provider routing, policy enforcement, and observability, uniformly, across every caller.
If you’re already thinking in terms of API gateways or service meshes, the mental model maps cleanly. An LLM proxy is to AI traffic what an API gateway is to REST services, except the stakes are higher, the payloads are semantically rich, and the failure modes are considerably less predictable.
A simplified view of the architecture looks like this:
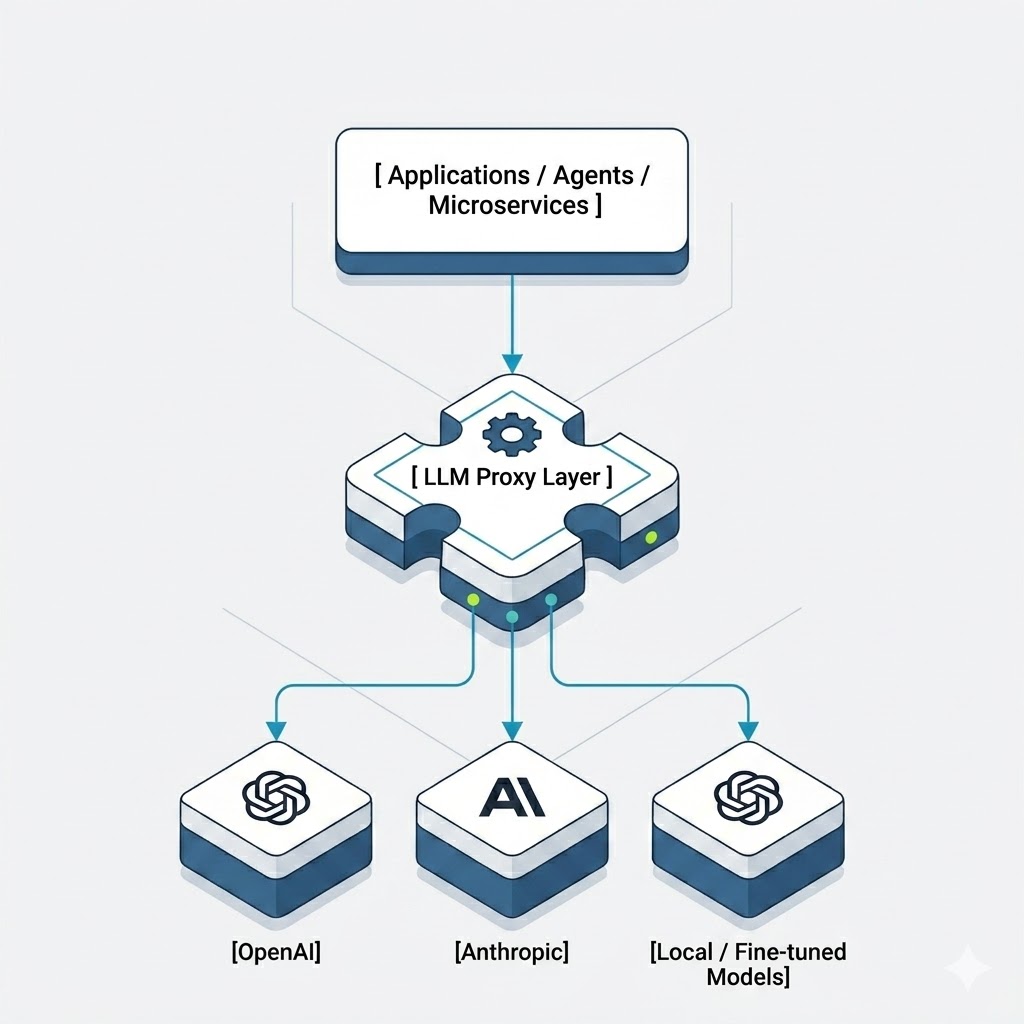
One entry point. Full control. Consistent behavior regardless of what’s running downstream.
Why This Problem Is Urgent Right Now
AI Sprawl Is Already Happening in Your Organization
In most enterprises, AI adoption isn’t centrally coordinated. It’s happening team by team. One squad integrates GPT-4o for summarization. Another evaluates Claude for code review. A data team wires up Gemini for structured extraction. Each team picks the provider that suits their latency, cost, or quality requirements at that moment.
The result is a sprawl of integrations, each with its own authentication logic, error handling, and retry strategies. Maintenance becomes painful. Behavior becomes inconsistent. When a provider changes its API or deprecates a model, you’re updating code in a dozen places.
An LLM proxy collapses that complexity into a single interface. Multi-model strategies become an operational decision at the proxy level, not a development effort spread across every team.
Sensitive Data Flowing Through Uncontrolled Endpoints Is a Real Problem
LLMs don’t just process trivial queries. They process customer inputs, internal documents, financial data, and proprietary business logic. Without a control layer in front of them, you’re exposing raw API endpoints to risks that are entirely preventable:
- Prompt injection attacks
- Accidental PII transmission to third-party providers
- Unauthorized API key usage
- Model outputs that violate your own content policies
A properly implemented LLM proxy acts as a defense-in-depth layer, inspecting inputs before they reach any model and filtering outputs before they reach any user. At N47, where we hold ISO 27001 certification, this kind of systematic security architecture isn’t an afterthought. It’s the baseline expectation for any production system we build or advise on.
Compliance Requirements Are Getting Real
The EU AI Act is no longer a horizon item. Enterprises operating in regulated environments need to demonstrate data traceability, controlled access to AI capabilities, and auditability of interactions. Without centralized logging and governance, that’s nearly impossible to prove.
An LLM proxy gives you a single point where policy enforcement, full request/response logging, and access controls can be applied at scale, rather than trying to retrofit compliance into every individual application after the fact.
Token Costs Scale Faster Than Teams Expect
LLM pricing is consumption-based, and the bill grows with every new feature, every new user, and every inefficient prompt. Without visibility into which teams are consuming what, costs become opaque. Developers inadvertently duplicate requests. Legacy integrations route everything to premium models when cheaper alternatives would do the job just fine.
A proxy gives you centralized cost tracking broken down by user, team, or application. It enables budget enforcement, quota management, and intelligent routing, so you’re automatically falling back to more cost-effective models when the task doesn’t justify a premium tier.
Core Capabilities of a Production-Grade LLM Proxy
Unified API Abstraction
Developers integrate once against the proxy’s standardized interface. Provider-specific quirks like authentication schemes, request formats, and response structures are abstracted away. Switching providers or adding new ones becomes a configuration change, not an engineering effort.
Intelligent Routing and Orchestration
Proxies can dynamically select models based on real-time signals: cost constraints, latency thresholds, task complexity, or current provider availability. A simple FAQ query routes to a lightweight, low-cost model. A complex multi-step reasoning task routes to a premium model. This happens transparently, without the calling application needing to know or care.
Security Guardrails
Enterprise-grade proxies enforce:
- Input sanitization and PII redaction
- Injection detection
- Output moderation
- Rate limiting
All of this is applied consistently across every request, regardless of which application made it. The alternative is implementing the same controls redundantly across every service, which inevitably leads to gaps.
Deep Observability
Token usage, latency distributions, error rates, and prompt patterns all become visible through a single observability surface. This is the data you need to debug production issues, optimize performance, and understand how AI features are actually being used, not just how you assumed they’d be used.
Governance and Access Control
Role-based access control at the proxy level means you can restrict which teams use which models, enforce organizational quotas, and manage API keys centrally rather than scattering credentials across every service’s environment config. It’s also the practical answer to shadow AI, teams spinning up AI integrations completely outside any organizational visibility.
Security Architecture: Defense-in-Depth for AI Systems
Security in AI systems requires a layered approach, and the LLM proxy is where that layering becomes operationally viable. The controls break down across four areas:
- Input controls: Prompt sanitization, injection detection, and PII redaction before any data leaves your environment
- Output controls: Toxicity filtering and data leakage prevention so model responses meet your content and compliance standards
- Runtime controls: Rate limiting and anomaly detection to protect against abuse and unexpected usage spikes
- Audit and compliance controls: Full request/response logging with the traceability needed for regulatory audits
The important distinction here is that implementing these controls at the proxy level is categorically different from doing it per-application. At the application level, you’re constantly playing catch-up as new services get built. At the proxy level, controls are applied once and inherited by everything.
Governance: From Experimental Tool to Managed System
The shift from “we’re experimenting with AI” to “AI is a managed organizational capability” is largely a governance problem, and LLM proxies are the mechanism through which that shift actually happens.
Policy-as-code means your governance posture evolves without requiring coordinated changes across every application. Audit trails give you a complete record of every AI interaction, which matters more and more as organizations move toward agentic AI systems where autonomous agents are making decisions and calling external tools on behalf of users. Standardization ensures consistent model behavior across different use cases, preventing the situation where two teams using “the same” AI capability get wildly different results because they’ve configured things differently.
As multi-agent architectures mature, where AI agents chain together, use tools, and interact with external services, the LLM proxy evolves from a traffic gateway into a full AI control plane. It becomes the layer that ensures safe autonomy at scale.
The Honest Trade-offs
LLM proxies add real value, but engineering teams should go in clear-eyed about the costs.
Every request through the proxy adds some latency. Inspection, routing logic, and logging aren’t free. Well-designed implementations keep this overhead minimal, but it’s a real consideration for latency-sensitive applications. Policy maintenance is also an ongoing operational responsibility: guardrails need to be tested, tuned, and updated as models and use cases evolve. Overly aggressive filters produce false positives that block legitimate requests and create friction for developers. And like any piece of infrastructure, the proxy itself requires monitoring, ownership, and operational maturity.
These aren’t reasons to avoid proxies. They’re reasons to implement them thoughtfully, with the same engineering rigor you’d apply to any critical piece of production infrastructure.
Where This Is Going
The LLM proxy is not a transitional architecture. As enterprises go deeper with AI capabilities, think real-time decision engines, tool-augmented agents, multi-model orchestration pipelines, the need for a centralized control plane only grows. The organizations that build this layer early will have a structural advantage: the ability to adopt new models, comply with new regulations, and scale AI usage without rebuilding their foundations every time something changes.