Every employee who travels for work knows the feeling: you’re back at your desk, a pile of receipts waiting, and you have to type it all in manually. Vendor name, date, amount and currency all entering one by one. The process is not complicated, just very tedious.
With AI becoming a natural part of modern software, automating exactly these kinds of small but repetitive tasks has never been more accessible. This post shows how to eliminate that friction using Spring AI and its integration with the Google VertexAI API.
The result is a focused feature that is easier to implement than you might expect and especially one that users genuinely appreciate.
The Hidden cost of manual expense entry
Giving up a few minutes of a work day to enter an expense report does not sound like a crisis. However multiplying those few minutes across every employee, every other trip to various events multiple times a month is what is adding up quite a lot of manual time.
The lost time alone is one thing. More damaging are effects such as late submissions that create overhead for the accounting team. Additionally, forgotten receipts lead to missing or incorrect amounts and the general friction builds a quiet frustration on both the employee and employer side.
In many companies, the bridge between a paper receipt and a digital record is still a spreadsheet or scattered PDFs. Employees fill in an Excel template, attach scanned receipts and email the whole thing to their manager or accounting department. Every month, the same file, the same columns, the same copy-pasting.
Even in companies that have moved to dedicated expense software, the core problem remains: Someone still has to read the receipt and type the data in. The software digitized the approval workflow, but not the manual entry step.
The question worth asking is whether modern AI can solve this with minimal overhead. As it turns out, yes and the implementation is simpler than most developers expect.
Choosing the Stack
The feature described in this post was built for Hello Today, N47’s All-in-One ERP for service providers. The goal was not to build a standalone AI product, but to extend existing expense workflow with a targeted integration that removes one specific piece of user friction.
The integration uses Gemini 2.5 Flash via the Google Vertex AI, integrated through Spring AI. The model hits an excellent tradeoff between performance and cost while remaining highly reliable at extracting structured data from documents. It is natively multimodal, which means it reads text directly from images without a separate preprocessing step. This matters especially for a feature that needs to handle any format a user might upload: a phone photo, a PDF invoice or a scanned document.
Additionally Spring AI provides a clean abstraction layer over the model providers due to a ChatModel interface. The underlying model is a configuration concern and not a code concern, meaning it can be swapped in the future without touching the integration logic, if a more suitable model arises.
Setting up the Integration
The overall project uses Spring Boot and Maven. So to properly integrate the Vertex AI into the project we need to add the following library dependency to the pom.xml enabling the usage of the API in the service layer:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-vertex-ai-gemini</artifactId>
</dependency>To complete the setup a separate configuration inside the application.yml file is necessary.
spring:
ai:
vertex:
ai:
gemini:
project-id: ${GCP_PROJECT_ID}
location: ${GCP_LOCATION:europe-west1}
transport: restThe GCP_PROJECT_ID and GCP_LOCATION environment variables point to the company-hosted Gemini deployment, keeping data within the organization’s GCP environment. This is especially important, since expense receipts could potentially contain sensitive data of the user.
Spring AI auto-configures the VertexAiGeminiChatModel bean from these properties without any other boilerplate client initialization necessary.
File Type Detection
Before sending anything to Gemini, the model needs to correctly identify the file’s MIME type to properly respond with any useful information. Through the service layer and setup users can upload any photo, PDF or other files which provides the receipt and gets saved as an array of bytes: byte[] fileData. To properly detect what these bytes initially represented we use an external library called Apache Tika. It reads the raw bytes directly:
private Media detectAndCreateMedia(byte[] fileData) {
Tika tika = new Tika();
String detectedMimeType = tika.detect(fileData);
MimeType mimeType = MimeTypeUtils.parseMimeType(detectedMimeType);
return new Media(mimeType, new ByteArrayResource(fileData));
}The result is then a Media object, which attaches files to the prompt inside Spring AI, while preserving the correct type metadata. Gemini receives the file knowing exactly what it is looking at to properly decipher the receipt.
Model Configuration
Calling the model itself is quite straightforward while keeping two major decisions in mind. The first is the temperature variable:
VertexAiGeminiChatOptions options = VertexAiGeminiChatOptions.builder()
.model("gemini-2.5-flash")
.temperature(0.0d)
.maxOutputTokens(2048)
.build();Temperature 0.0 eliminates randomness entirely. This is an extraction task, not a creative one, so the output needs to be consistent and machine-parseable every single time the prompt executes. This single setting is the most important configuration decision for this use case.
The second decision is an async execution. The call itself uses a so-called CompletableFuture to keep it non-blocking during the reasoning of the model:
return CompletableFuture.supplyAsync(() -> {
Prompt prompt = new Prompt(userMessage, options);
ChatResponse response = chatModel.call(prompt);
return response.getResult().getOutput().getText();
});Both the text instruction and the raw files arrive together in a single UserMessage. Gemini receives everything in one multimodal request and reasons across all of it simultaneously.
Prompt Engineering
The model integration is straightforward. The prompt is where the real work happens.
The overall goal is to make Gemini behave like a deterministic API endpoint, not a conversational assistant. That starts with framing:
You are a data extraction API. Your output will be parsed directly by a machine.
This framing alone dramatically reduces unwanted behavior like markdown wrapper, explanatory text or JSON wrapped in a code block.
Depending on how many files the user uploads, the service selects one of two prompt variants. For a single receipt, the prompt defines the output schema explicitly:
Extract data into a JSON object with the exact following keys:
{
"name": "The merchant or vendor name.
Do NOT extract the customer/payer name.",
"description": "A short summary of items purchased.
If there are 5 or fewer items, list them with
quantities (e.g. '2x Coffee'). If there are MORE
than 5, summarize by category instead.",
"dateOfExpense": "The date on the receipt (YYYY-MM-DD).
If unknown, return empty string.",
"price": The total amount (float),
"currency": The 3-letter ISO currency code (e.g. CHF, USD, EUR).
}When a user uploads multiple files for the same trip, a second variant instructs Gemini to aggregate rather than extract. Instead of returning one entry per file, it produces a single coherent summary. For example: a train ticket, a hotel receipt and a dinner bill become “Trip to Zurich” with a combined total. The structure of the returned JSON stays identical while only the instructions change.
Both variants include a RULES block to enforce the output format:
RULES:
1. "dateOfExpense" MUST be in
strict ISO-8601 format (YYYY-MM-DD).
2. "price" must be a number — no currency symbols.
3. Return ONLY a valid, raw JSON string.
4. Do NOT use Markdown formatting.
5. Do NOT include any conversational text.
Start with { and end with }.
6. Detect the language of the document and
write "name" and "description" in that SAME language.Rule 6 is a single line that delivers a significant UX benefit with zero extra code. A German receipt returns a German description, a French invoice returns French text automatically with no additional translation logic anywhere in the application.
Edge Cases
Not every receipt arrives in perfect condition. A few edge cases shaped the final implementation:
- Empty or unreadable files are cought before the model is ever called. If all provided file IDs resolve to empty content, the request fails fast with a clear error. Calling a model with no data service no purpose and wastes tokens.
- Unknown dates presented a subtler problem. Early versions instructed Gemini to fall back to today’s date when no date could be found. An empty string replaces this value instead. A hallucinated date that looks plausible is worse than a blank field the user fills in themselves, thus possibly introducing incorrect data silently.
- Finally, if Gemini returns a response that cannot be deserialized into the expected structure, an empty object is returned rather than surfacing a
500 error. The user loses the pre-fill option, but can still enter the expense manually.
Results and Examples
To make this concrete, consider a single-receipt upload. A user photographs a Hilton Hotel stay receipt after a client event in San Francisco in English, dated 20th November 2019, totaling for $828.72. The mock receipt was generated using Receipt Faker. Here is the raw JSON that Gemini successfully extracted from it:
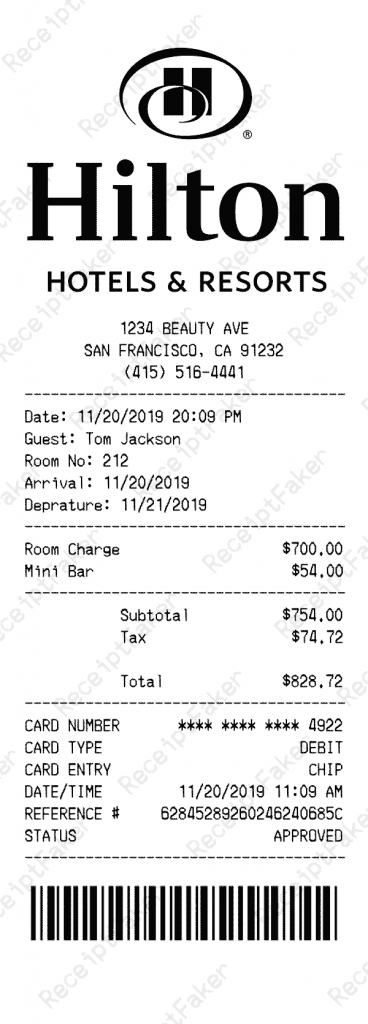
"data": {
"extractExpenseData": {
"name": "Hilton HOTELS & RESORTS",
"description": "Room Charge, Mini Bar in San Francisco",
"dateOfExpense": "2019-11-20",
"price": 828.72,
"currency": "USD",
"__typename": "ExtractExpenseDataResponse"
}
}The description returns in English automatically, matching the source of the document, with no locale configuration needed. It is returned quite quickly while being correct in every entity.
Model Robustness
The natural question is how reliably Gemini handles real-world documents, since these vary in quality having faded text, poor lighting or even handwriting. In testing, the model held up considerably better than expected.
A particularly striking example: a handwritten receipt from the early 1990s, with amounts in “Deutsche Mark”. Gemini read it correctly, extracted the total, and identified DM as the currency despite the fact that “Deutsche Mark” has not been in circulation since 2002. It did not guess, it did not hallucinate a modern equivalent.
For a feature running on what is considered a lightweight model in the Gemini lineup, that level of robustness across document age, quality and format is genuinely impressive and means the feature works reliably without any preprocessing or quality checks on the uploaded files.
Real-World Impact
The complete integration, counting the service methods, DTO’s, GraphQL schemas and tests comes to roughly 200 lines of code. Most of the intelligence lives in the prompt and in Gemini itself.
User feedback has been consistently positive. Expense extraction is one of the features users bring up unprompted, due to removing something genuinely annoying from their day-to-day workflow.
The broader lesson is worth stating plainly: AI value does not require a standalone AI product. A well-scoped integration with a capable model can remove real friction from a real workflow with a fraction of the effort that a dedicated document processing pipeline would require. The key is identifying the right problem: Converting repetitive manual work into an automated process.
Conclusion
Manual expense entry is tedious, error-prone and completely solvable. A focused integration with a rather simple Gemini Model 2.5 Flash and Spring AI can automate the data extraction step with minimal code while providing surprisingly good results out of the box, supporting a wide range of document types and conditions.
Extending the feature further is largely a matter of adjusting the prompt such as multi-file aggregation, automatic language detection or even currency converting with the current rate of exchange.
The hardest part of the whole implementation is writing a prompt that consistently produces machine-readable output. Once that is in place, the rest falls into line quickly.
Get in touch
If you are thinking about where AI could remove a similar friction point in your product, get in touch – we are happy to hear about your current approach or to help you find the right one.



