In today’s data-driven world, organizations are dealing with ever-growing volumes of data that need to be processed efficiently and reliably. Whether it’s analyzing user behavior in real time, transforming large datasets for reporting, or building machine learning pipelines, modern data systems must be flexible, scalable, and maintainable. This is where Apache Beam comes into play.
Apache Beam is an open-source, unified programming model designed to simplify large-scale data processing. It allows developers to define both batch and stream processing pipelines using a single abstraction, which can then be executed on various distributed processing backends. In this blog post, we’ll explore what Apache Beam is, why it’s useful, and how it fits into the modern data ecosystem.
What is Apache Beam?
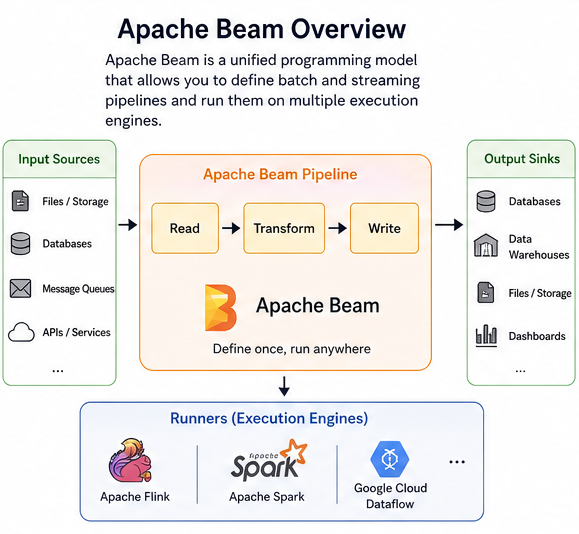
Apache Beam is a programming model and set of SDKs for defining and executing data processing pipelines. Instead of tying your data processing logic to a specific execution engine, Beam lets you write your pipeline once and run it on multiple runners such as Apache Flink, Apache Spark, or Google Cloud Dataflow.
The key idea behind Beam is separation of concerns:
- You define what your data processing pipeline should do.
- The runner decides how to execute it efficiently.
This abstraction allows teams to avoid vendor lock-in and adapt to changing infrastructure needs without rewriting core business logic.
Why Use Apache Beam?
1. Unified Batch and Streaming
Traditionally, batch and stream processing required separate systems and codebases. Apache Beam unifies both paradigms under a single model. This means you can write one pipeline that works for:
- Historical data (batch)
- Real-time data (streaming)
Beam handles the complexities of event time, windowing, and late data, making it easier to build consistent pipelines.
2. Portability Across Runners
Beam pipelines are portable. You can run the same pipeline on different execution engines (called runners), such as:
- Apache Flink
- Apache Spark
- Google Cloud Dataflow
This flexibility is especially valuable for organizations that want to avoid being locked into a single vendor or need to migrate infrastructure over time.
3. Scalability
Because Beam pipelines are executed on distributed systems, they can scale horizontally to process massive datasets. Whether you’re working with gigabytes or petabytes of data, Beam enables efficient parallel processing.
4. Advanced Windowing and Time Semantics
Handling time correctly in streaming systems is notoriously difficult. Beam provides robust support for:
- Event time processing
- Windowing (fixed, sliding, session windows)
- Watermarks to track progress
- Triggers to control output timing
This allows developers to build accurate and reliable real-time analytics systems.
Core Concepts in Apache Beam
To understand how Apache Beam works, it’s important to get familiar with its core abstractions.
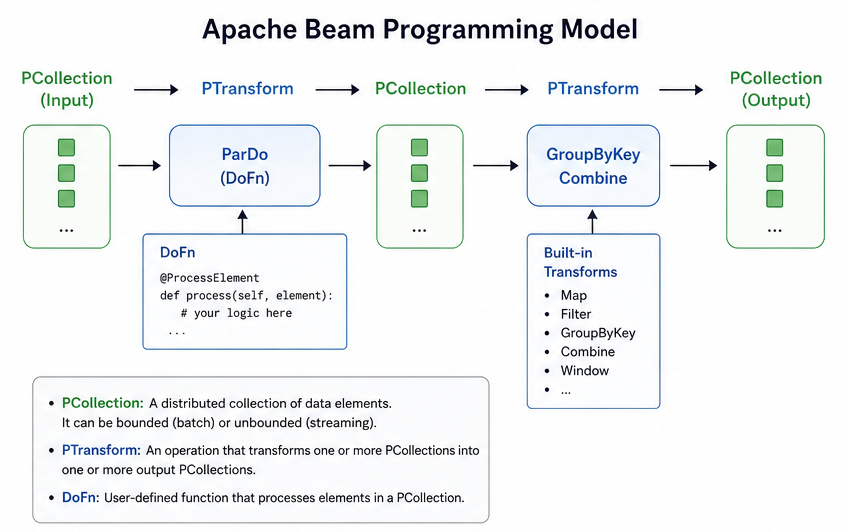
1. Pipeline
A pipeline is the overall data processing workflow. It defines the sequence of steps that transform input data into output data.
2. PCollection
A PCollection represents a distributed dataset. It can be bounded (batch) or unbounded (streaming). Think of it as a large, immutable collection of data elements.
3. PTransform
A PTransform defines an operation applied to a PCollection, such as filtering, grouping, or aggregating data. Common transforms include:
- Map
- Filter
- GroupByKey
- Combine
4. DoFn
A DoFn (short for “Do Function”) is a user-defined function that processes elements in a PCollection. It is used within transforms like ParDo to define custom logic.
5. Runner
The runner is the execution engine that actually runs your pipeline. Beam supports multiple runners, enabling portability and flexibility.
Example Workflow
A typical Apache Beam pipeline might look like this:
- Read data from a source (e.g., a file, database, or message queue)
- Apply a series of transformations (filtering, mapping, aggregating)
- Write the results to a sink (e.g., a database, data warehouse, or file system)
For example, imagine you want to process clickstream data:
- Read events from a streaming source like Kafka
- Group events by user
- Calculate session durations
- Output results to a dashboard or analytics system
With Beam, this entire workflow can be expressed in a single, unified pipeline.
Batch vs. Streaming in Beam
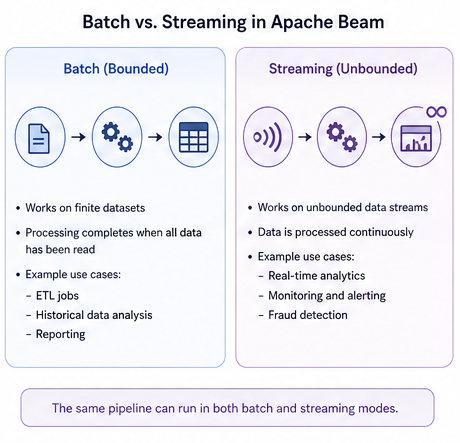
One of Beam’s most powerful features is its ability to treat batch and streaming as two sides of the same coin.
Batch Processing
- Operates on bounded datasets
- Typically used for historical analysis
- Example: processing logs from the past month
Streaming Processing
- Operates on unbounded datasets
- Processes data in real time
- Example: monitoring live user activity
Beam’s model allows you to write pipelines that can seamlessly switch between these modes, reducing duplication and simplifying maintenance.
Windowing and Triggers
In streaming systems, data doesn’t always arrive in order. Apache Beam addresses this challenge with windowing and triggers.
Windowing
Windowing divides data into logical chunks based on time. Common window types include:
- Fixed windows (e.g., every 5 minutes)
- Sliding windows (overlapping intervals)
- Session windows (based on user activity gaps)
Triggers
Triggers determine when results for a window should be emitted. This is important for handling late-arriving data and ensuring timely output.
Together, windowing and triggers provide fine-grained control over how streaming data is processed and emitted.
Supported SDKs
Apache Beam provides SDKs for multiple programming languages:
- Java (most mature)
- Python (widely used and actively developed)
- Go (growing ecosystem)
Each SDK allows developers to define pipelines using familiar language constructs while leveraging Beam’s unified model.
When Should You Use Apache Beam?
Apache Beam is particularly useful in the following scenarios:
1. Real-Time Analytics
If you need to process and analyze data as it arrives (e.g., monitoring user behavior, fraud detection), Beam’s streaming capabilities are highly valuable.
2. ETL Pipelines
Beam is well-suited for Extract, Transform, Load (ETL) workflows, especially when dealing with large datasets and complex transformations.
3. Event-Driven Systems
Applications that rely on event streams, such as IoT systems or microservices architectures, benefit from Beam’s ability to handle unbounded data.
4. Cross-Platform Portability
If you want the flexibility to switch between processing engines without rewriting your pipeline, Beam provides a strong abstraction layer.
Challenges and Considerations
While Apache Beam offers many advantages, it’s not without challenges.
1. Learning Curve
Beam introduces new concepts like windowing, watermarks, and triggers, which can be complex for beginners.
2. Debugging Complexity
Because pipelines run on distributed systems, debugging can be more difficult compared to local processing.
3. Runner Differences
Although Beam aims for portability, not all runners support all features equally. It’s important to understand the limitations of your chosen runner.
Apache Beam in the Modern Data Stack
Apache Beam plays a key role in modern data architectures. It often sits between data ingestion systems (like Kafka) and storage/analytics systems (like BigQuery or data lakes).
A typical architecture might look like this:
- Data ingestion via message queues or APIs
- Processing and transformation using Beam
- Storage in data warehouses or lakes
This makes Beam a powerful component for building scalable, end-to-end data pipelines.
Conclusion
Apache Beam provides a powerful and flexible way to build scalable data processing pipelines. By unifying batch and streaming under a single model, it simplifies development and reduces duplication. Its portability across multiple runners ensures that your pipelines remain future-proof and adaptable.
While there is a learning curve, especially around time-based processing concepts, the benefits often outweigh the complexity for teams working with large-scale or real-time data.
If you’re building modern data pipelines and want a consistent, scalable, and portable approach, Apache Beam is definitely worth exploring.
By understanding its core concepts and strengths, you can leverage Apache Beam to create robust data processing systems that meet the demands of today’s data-intensive applications.



